
Introduction
언어 모델은 최근 다양한 분야에서 매우 큰 영향력을 보이며, 특히 Large Language Model(LLM) 형태로 크게 발전해왔다. 일반적으로 LLM에서는 decoder-only Transformer 구조가 가장 널리 활용되고 있으며, 이 구조는 key-value (KV) cache를 통해 매 단계에서 과거 계산을 재사용하게 만들어 준다. 그러나 시퀀스 길이가 커질수록, 모든 layer에 대해 KV cache가 증가하게 되어 GPU 메모리를 크게 소모하고, 긴 context를 다루는 시나리오에서 prefilling 시간이 기하급수적으로 늘어나는 문제가 존재한다.
본 논문에서는 이 문제를 해결하기 위한 새로운 접근인 YOCO(You Only Cache Once) 구조를 소개한다. YOCO는 decoder를 두 부분으로 분리하는, 즉 decoder-decoder 형태의 구조를 제안한다. 첫 번째 부분을 self-decoder, 두 번째 부분을 cross-decoder라고 부른다. 본문의 요지를 간략히 정리하면 다음과 같다:
- YOCO는 self-decoder에서 전역적으로 단 한 번만 KV cache를 생성한다.
- cross-decoder에서는 self-decoder가 만든 KV cache를 cross-attention으로 재사용한다.
- 이러한 분리를 통해 긴 sequence에서 GPU 메모리 사용량을 크게 줄이고, prefilling 단계 시간을 획기적으로 단축한다.
아래에서는 YOCO 구조의 핵심 개념과 실험 결과, 그리고 구체적인 구현상의 이점을 자세히 살펴본다.
Background
기존 문제점: KV Cache 메모리와 Prefilling 시간 증가
- Decoder-only Transformer를 사용하면, layer마다 KV cache가 누적된다. 예를 들어 layer가 L개이고, 토큰 길이가 N이라면, 모든 step에서 N×L 크기의 KV cache가 필요하다.
- 시퀀스 길이를 수십만, 수백만으로 확장하려고 할 때, GPU 메모리를 넘어서는 KV cache가 요구된다.
- 뿐만 아니라 긴 문서를 한 번에 입력으로 넣는 prefilling 단계에서는 계산 복잡도가 O(N^2)에 해당하여 시간이 매우 오래 걸린다.
YOCO: Decoder-Decoder Architecture
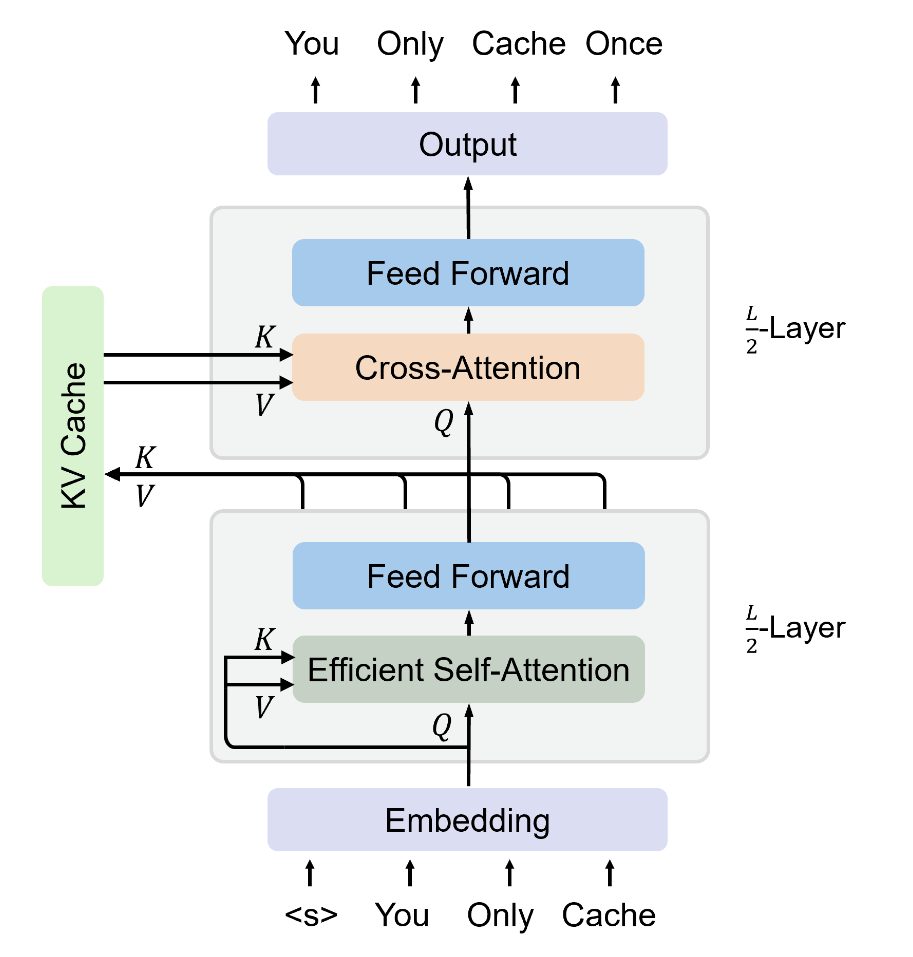
YOCO의 큰 특징은 “한 번만 전역 KV cache를 만든다(You Only Cache Once)”는 점이다. 구조를 2개의 블록으로 구성하는데,
- Self-Decoder
- 입력 시퀀스에 대해 효율적인 self-attention(예: sliding-window attention 또는 gated retention)을 수행한다.
- 이를 통해 최종적으로 전역적으로 재사용될 KV cache를 생성한다.
- self-decoder는 window 크기 등으로 메모리가 O(1) 수준만 필요한 효율적 구조를 활용한다.
- Cross-Decoder
- self-decoder가 만든 KV cache를 입력으로 받아 cross-attention을 수행한다.
- 각 cross-decoder layer는 동일한 전역 KV cache를 재사용한다.
- 따라서 KV cache가 layer마다 누적될 필요가 없으므로 메모리가 크게 절감된다.
동작 방식
- 입력 시퀀스가 주어지면, self-decoder가 효율적인 self-attention을 통해 중간 표현을 계산한다.
- 중간 표현에서 한번에 글로벌 KV를 만든다.
- 이후 cross-decoder는 이 글로벌 KV를 참조해 cross-attention을 한다.
결과적으로 외부에서 보기에는 decoder-only와 유사하게 토큰을 생성하지만, 내부적으로는 KV cache가 중복 생성되지 않는다.
Inference Advantages
- KV Cache 메모리 절감
- Transformer는 N개의 토큰 각각을 모든 L layer에 대해 KV로 저장해야 하므로, 메모리가 O(N×L)로 확장된다.
- YOCO는 한번(global)만 KV를 저장해, O(N + L) 수준으로 크게 줄인다(실제로는 sliding-window 크기 등 자잘한 항이 더해질 수 있으나, N이 매우 클 때 L 대비 현저히 크게 되고, KV cache가 사실상 N에 선형 비례인 정도).
- Large scale LLM(예: 수십억~수백억 파라미터)에서, 수십만 길이의 시퀀스를 처리할 때 GPU 메모리를 획기적으로 줄일 수 있다.
- Prefilling 시간 단축
- 기존 Transformer는 prefilling 단계에서 모든 layer에 대해 self-attention을 O(N^2)로 처리해야 한다.
- YOCO에서는 self-decoder 만으로도 충분히 시퀀스 정보를 압축할 수 있고, cross-decoder는 prefilling 시점에서 스킵하거나, 혹은 매 step 마다가 아니라 한 번만 거치도록 한다(즉, self-decoder를 지난 뒤 cross-decoder에서는 incremental decoding).
- 결국 prefilling의 시간 복잡도가 O(N)으로 낮아지기 때문에, 예컨대 512K length를 입력으로 넣어도 수초 내로 처리 가능하다는 프로파일링 결과를 보인다.
- Throughput 증가
- 메모리 사용량이 감소하므로, batch size를 늘려서 병렬 처리량을 높이는 데 이점이 있고, cross-decoder가 global KV를 재활용하므로 연산 효율이 좋아진다.
Self-Decoder 설계: Sliding-Window 혹은 Gated Retention
YOCO를 구성할 때 self-decoder 안에서 어떤 방식의 “효율적 self-attention”을 쓸지는 선택지가 있다. 이 논문에서는 대표적으로 두 방법을 제안한다:
- Sliding-window attention
- local window 크기 C를 정해두고, 각 토큰이 바로 이전 C개의 토큰만을 attend한다.
- KV cache가 C×L 정도이므로(각 layer마다 C개의 토큰), N에 비해 상수가 되어, 길이에 따른 확장이 없다.
- Gated retention
- retention 구조에 gating을 추가해, recurrent하게 hidden state를 업데이트하는 방식.
- chunkwise나 parallel 등 다양한 계산 모드를 지원하면서, inference 시 O(1) KV 크기를 유지한다.
- 실험에서 이 방법이 sliding-window 대비 일반 도메인 텍스트에 더 유리한 성능을 보이기도 했다.
실험 결과
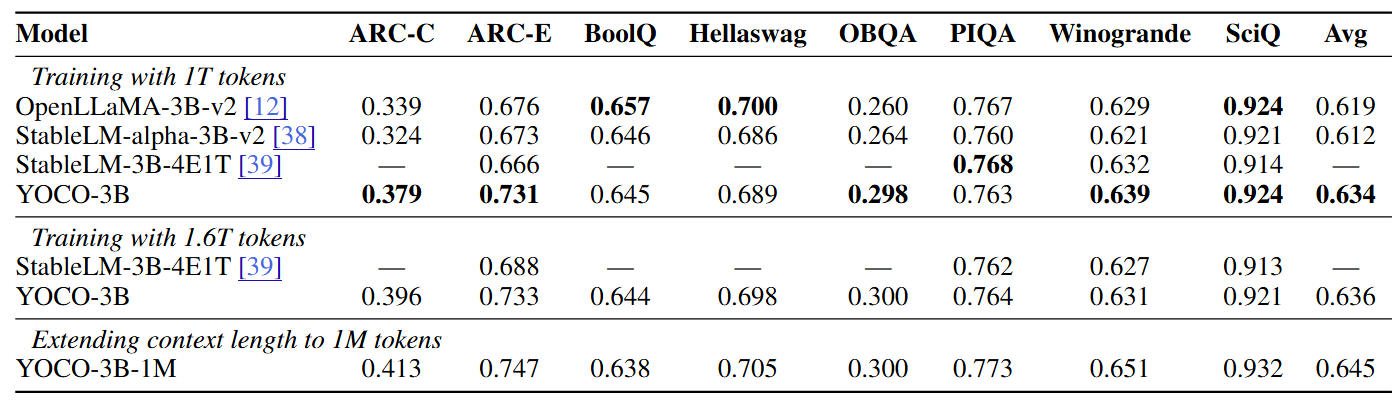
1. Language Modeling 성능
- 3B 파라미터 규모 YOCO 모델을 1조~1.6조 토큰으로 학습했을 때, StableLM 3B 등 Transformer 기반 모델과 견줄 만한 성능을 보였다.
- 다양한 벤치마크 (ARC, BoolQ, Hellaswag 등)에서 기존 LLM 수준의 정확도를 달성했다.
2. Scaling 성능

- 1.6억~130억 파라미터 구간에서 Transformer, YOCO로 각각 모델을 학습하여 scaling curve를 비교했다.
- YOCO도 parameter가 커질수록 점진적으로 loss가 낮아지며, Transformer에 상응하는 성능이 보인다.
3. 1M-length Context

- YOCO 구조를 100만 길이로 확장해 Needle in a haystack 테스트를 수행한 결과, 거의 완벽에 가까운 long context retrieval 성능을 달성했다.
- 추가로 multi-needle 환경에서도 우수한 결과를 나타냈다.
4. Inference Profiling
가장 큰 장점인 inference 효율 향상은 아래와 같다:
- GPU 메모리: 3B 모델 기준, 1M context를 처리할 때 Transformer는 100GB 이상이 요구되지만 YOCO는 약 12GB로 처리 가능했다(9배 이상의 절감). layer 수가 많아질수록 이 격차는 더욱 커진다.
- Prefilling Latency: 512K context에서 Transformer가 약 180초가 걸리던 것을, YOCO는 6초 미만으로 크게 감소시켰다.
- Throughput: context가 길어질수록 Transformer의 throughput은 크게 떨어지는데, YOCO는 최대 9배 이상의 높은 throughput을 보인다.
결론 및 요약
YOCO는 “You Only Cache Once” 아이디어를 통해 decoder를 self-decoder와 cross-decoder로 분할하는 새로운 구조이다. 이를 통해 각 layer마다 누적되는 KV cache 부담을 없애고, 긴 시퀀스에서의 prefilling 시간을 획기적으로 단축한다. 또한 최종 성능 면에서도 기존 decoder-only Transformer와 대등하거나 더 우수한 결과를 얻을 수 있음을 다양한 스케일(모델 크기, 학습 토큰 수, context 길이)에서 보였다.
핵심 요약:
- Decoder-Decoder 구조:
- self-decoder: 효율적 self-attention으로 전역 KV cache 생성
- cross-decoder: 해당 KV cache를 재사용해 cross-attention
- Inference 시, KV cache가 한 번만 생성되므로 긴 context에서 GPU 메모리 사용량을 매우 줄인다.
- Prefilling 단계가 O(N) 복잡도로 이루어져, 매우 긴 입력 길이에서도 속도 개선폭이 크다.
- 다양한 벤치마크 및 스케일링 실험을 통해 Transformer와 동등 이상의 성능과 뛰어난 효율을 시현했다.
- 최대 1M 토큰 길이까지도 확장 가능함을 보였고, needle retrieval 실험에서 높은 정확도를 달성했다.
결국 YOCO는 차세대 LLM에 적합한 방향으로, 대규모 시퀀스 지원에 필수적인 낮은 메모리 사용량과 높은 속도를 동시에 만족시킨다. 오픈 도메인 QA나 code completion 같은 수십~수백만 길이의 context가 필요한 환경에 유용하며, 실제 서비스를 운영하는 입장에서도 GPU 자원을 크게 절약하여 비용 효율적이라는 점에서 주목할 만하다.



