
Introduction
강화학습은 일반적으로 환경과 상호작용하면서 데이터를 수집하고, 이를 바탕으로 에이전트를 학습시키는 방식으로 이루어져 왔다. 그러나 사람이 새로운 기술을 배우는 상황을 떠올려 보면, 직접 시행착오를 겪기 이전에 “교과서”나 “튜토리얼 책”을 통해 지식을 습득하고 이를 머릿속에서 리허설(Rehearse)해보는 과정을 거친다. 이 논문에서는 이러한 인간의 학습 방식을 모사해, 환경과 직접 상호작용하지 않고도 “튜토리얼 책”에 담긴 지식을 활용해 정책을 학습하는 Policy Learning from tutorial Books(PLfB) 문제를 새롭게 제시하고, 이를 해결하기 위한 URI(Understanding, Rehearsing, Introspecting) 프레임워크를 제안한다.
문제: 교과서(튜토리얼 책)에서 직접 정책을 학습하기
강화학습에서는 대개 환경의 동작원리를 몰라도 좋지만, 충분한 데이터 수집(환경과의 상호작용)이 필요하다. 반면, 본 연구에서는 실제 환경에서 상호작용 데이터를 많이 모으지 않고도, 이미 정리된 지식(텍스트, 예: 튜토리얼 책)을 활용하여 정책을 학습하는 시도를 한다. 이를 Policy Learning from tutorial Books(PLfB)라 정의한다.
PLfB를 달성하려면, 사실상 게임(또는 환경) 룰, 정책(전략), 보상 등에 대한 정보가 텍스트에 잘 정리되어 있어야 한다. 하지만 텍스트 형태로 된 문서를 곧바로 강화학습 정책으로 바꾸는 것은 쉽지 않다. 저자들은 이 문제를 풀기 위해서, 마치 사람이 책을 읽고 상상 연습을 한 뒤, 그 결과를 복기하면서 스스로를 교정하는 과정을 흉내 내는 세 단계 접근법을 개발했다.
세 단계 접근법: URI
이 논문의 핵심 기여는 URI(이해, 리허설, 자기성찰)라는 세 단계 프레임워크입니다.
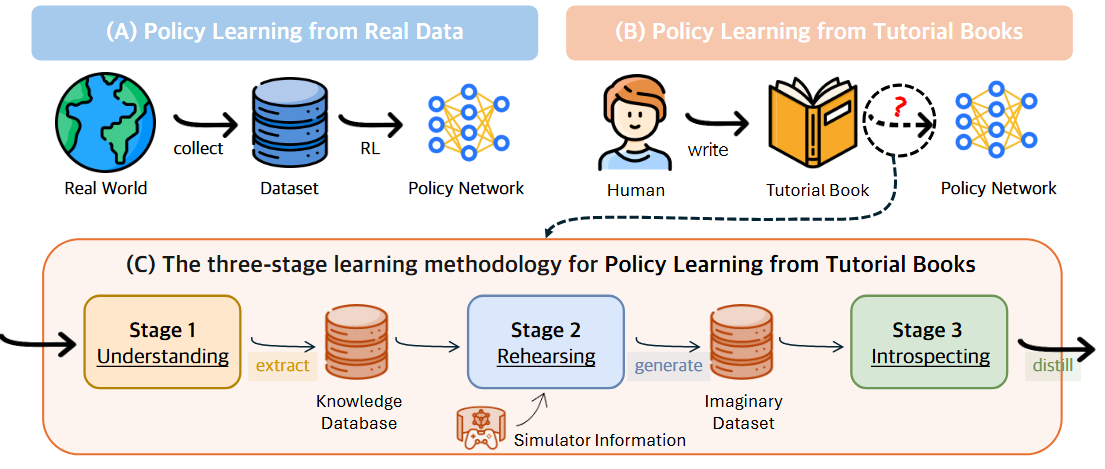
- 이해(Understanding)
- 튜토리얼 책 속 문단(Paragraph)을 하나씩 읽고, 거기서 중요한 지식을 추출한다.
- 추출된 지식은 정책, Dynamics 모델(환경 전이), 보상 등에 대한 코드(pseudocode) 형태로 표현된다.
- 예: “슈팅할 때 골문 정면이면 골 확률이 높음” → 보상/환경 규칙 코드를 짜듯이 요약
- 여러 문단에서 뽑힌 유사 지식은 중복 혹은 모호함을 정리하여 더 간결하고 추상화된 코드로 “집약(Aggregation)”한다.
- 리허설(Rehearsing)
- 이 단계에서는 추출된 코드 지식을 활용해, 마치 실제 환경이 존재하는 것처럼 상상(Imagination)을 통해 가상의 트레젝터리를 생성한다.
- 구체적으로, 현재 시점에서 상태가 주어지면(혹은 아무 상태를 하나 선정), 정책에 대한 코드를 통해 어떤 행동을 할지 결정하고, 환경 Dynamics 코드를 통해 다음 상태를 생성하며, 보상 코드를 통해 보상을 산출한다.
- 이 일련의 과정으로 얻어진 가상의 데이터셋(Imaginary Dataset)이 최종적으로 수만~수십만 개의 (상태, 행동, 보상, 다음 상태) tuples가 된다.
- 자기성찰(Introspecting)
- 그러나 텍스트 기반 생성 과정에는 Hallucination이 섞여 있을 수 았다. 예: 잘못된 상태 전이가 생길 수 있고, 보상 계산이 틀릴 수도 있다.
- 따라서 마지막 단계에서는 오프라인 강화학습 기법을 적용해 생성된 가상 데이터를 다시 살펴보고, 불확실성이 큰 부분(LLM 출력이 불안정해 보이는 전이·보상)은 페널티를 준다.
- 최종적으로 CIQL(Conservative Imaginary Q-Learning)이라는 알고리즘을 사용해, 가상의 오프라인 데이터로부터 정책망을 학습한다. 이 과정을 통해 LLM이 만들어낸 오류나 신뢰도 낮은 구간을 완화하고, 더 안정적인 정책을 얻게 된다.

실험 결과
환경 1) Tic-Tac-Toe

- 구현: 게임판은 3×3이고, 승리 시점을 제외하면 계속 번갈아 가상의 보드를 업데이트. 책(튜토리얼)에는 최적 전략(미니맥스) 설명이 포함되어 있음.
- 비교:
- LLM-as-agent: GPT-3.5에 매턴 상태를 요약하여 행동을 직접 출력
- LLM-RAG: 위와 동일하나, 추가로 책에서 원하는 문단을 조회(RAG)하여 참조 후 행동
- URI: 세 단계 과정을 거쳐 최종 policy network를 얻음
- Minimax(최적), Minimax + Noise, Random 등
- 결과:
- URI가 LLM-as-agent 대비 net win rate +66%, LLM-RAG 대비 +44% 등으로 크게 우세.
- 최적(Minimax) 전략과 비교해도 상당히 높은 승률을 유지.
환경 2) Google Research Football
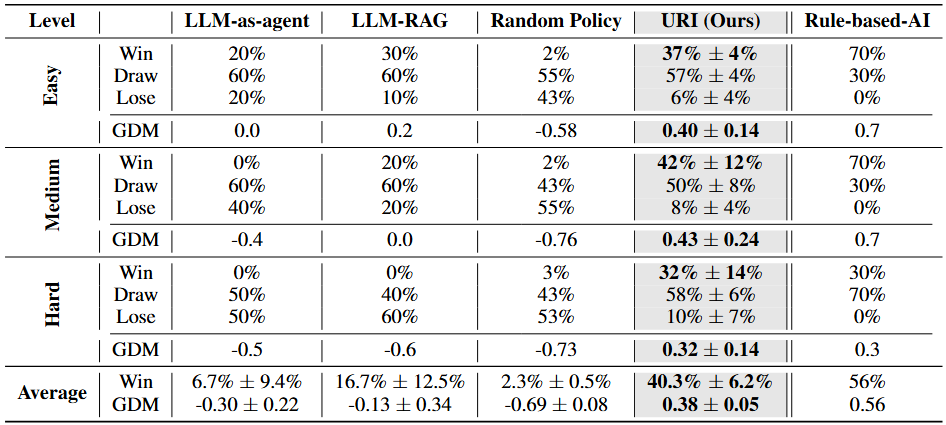
- 특징: 실제 축구에 가까운 물리·규칙을 시뮬레이션하며, 상태가 연속적이고, 난이도(easy/medium/hard)별로 내장 AI가 존재.
- 데이터: 튜토리얼 책(축구 관련 서적)을 웹에서 수집(RedPajama), 약 90권.
- 비교:
- LLM-as-agent, LLM-RAG 등이 10~20% 내외의 승률밖에 못 낼 때,
- URI는 Easy~Hard 난이도 AI 상대로 평균 40%의 승률, 골 득실도 상대적으로 크다. hard 모드에서도 30% 이상 승률 기록.
이처럼, 단순 보드게임부터 물리적 상호작용이 많은 축구 시뮬레이션까지 “튜토리얼 텍스트”만으로 합리적인 정책을 학습할 수 있음을 증명했다. 또한 LLM으로 매 스텝 행동을 직접 내는 방식은 매우 느렸지만(매 행동당 2~4초), URI의 최종 정책망은 매우 빠르게(매 행동당 약 0.009초) 동작했다.
추가 논의 및 한계
- 튜토리얼 책의 품질
- URI는 책에 충분히 정확한 정책/규칙/보상/동적 모델이 들어 있다고 가정한다. 책이 편향·부실하면 기대만큼 효과가 나오기 어렵다.
- 책의 품질을 정량적으로 측정하는 방안은 향후 과제.
- 확장 가능성
- 시뮬레이션 축구 환경처럼 복잡한 도메인에서도 동작함을 보였으나, 로봇 등 더 복잡한 현실 환경에도 적용 가능할지 연구 여지가 많다.
- 사람의 학습처럼 실제 환경 상호작용 + 텍스트 정보를 함께 쓰는 방식으로도 확장할 수 있을 것으로 보인다.
- 실무적 활용
- 에이전트가 특정 게임·작업을 수행해야 할 때, 이미 잘 정리된 매뉴얼/튜토리얼 문서가 존재한다면, URI 기반 학습이 큰 잠재력을 가질 것.
결론
이 논문에서는 튜토리얼 책으로부터 직접 정책을 학습한다는 새로운 문제(PLfB)를 정의하고, 이를 URI(이해→리허설→자기성찰)라는 프레임워크로 해결했다는 점을 핵심 기여로 제시했다.
- 이해(Understanding) 단계: 텍스트를 코드 형태로 정리해 지식 DB 구성
- 리허설(Rehearsing) 단계: 지식을 토대로 상태·행동·보상을 상상으로 생성
- 자기성찰(Introspecting) 단계: 가상 데이터에 대한 불확실성을 추정·벌칙하여 보완, 정책망 학습
Tic-Tac-Toe 및 축구(Football) 시뮬레이션 실험에서 URI는 기존 LLM 기반 정책보다 훨씬 우수하고, 실제 고정된 시뮬레이터 AI와도 경쟁이 가능함을 보였다. 이 방법론은 앞으로, 로보틱스·게임 등 다양한 분야에서 문서화된 지식을 활용해 실제 상호작용 횟수를 줄이는 새로운 길을 열 것으로 기대된다.



