
Introduction
최근 LLM 모델의 학습 과정에서 사용자 선호(또는 Reward)와 일치하도록 모델을 튜닝하는 preference optimization 기법이 활발히 연구되고 있다. RLHF 또는 DPO와 같은 파이프라인은 높은 퀄리티의 답변을 만들어내는 데 효과적이지만, 동시에 모델의 출력 다양성이 급격히 감소하는 현상이 여러 연구에서 보고되었다. 이런 현상을 Alignment Collapse라고 부르기도 한다.
Problem: Diversity의 감소
기존 reinforcement learning이나 preference optimization 방법들은 최적의 보상(Reinforcement)만을 강조해, 결과적으로 모델 출력 분포가 한정된 일부 토큰·패턴에 집중하는 경향이 발생한다. 예컨대, creative writing이나 문장 생성 시 똑같은 어휘나 구조의 문장이 반복되는 문제가 대표적이다. 이러한 단조로운 분포는 여러 애플리케이션(예: synthetic data generation, 아이디어 발상 등)에서 문제가 될 수 있다.
핵심 아이디어: Diverse Preference Optimization (DivPO)
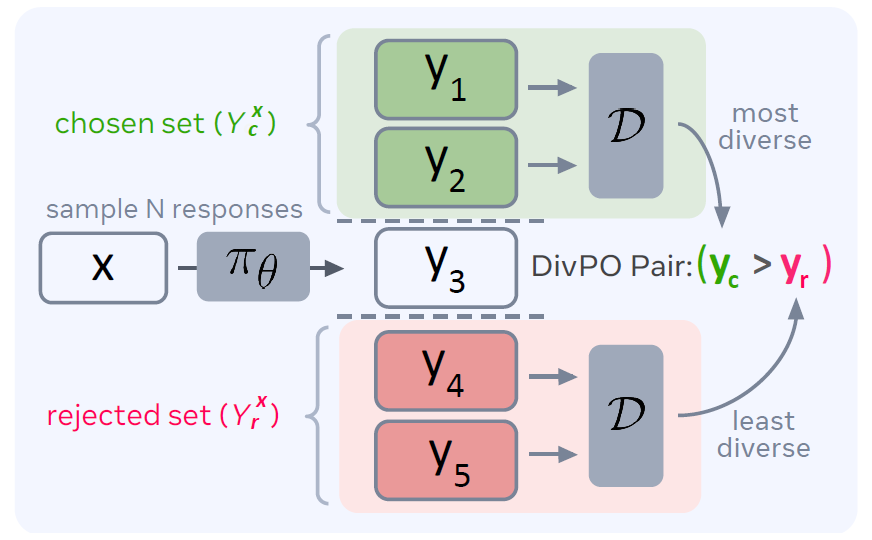
Diverse preference optimization (DivPO)는 퀄리티 + 다양성 두 목표를 함께 달성하고자 하는 학습 기법이다. 기존 DPO 기법은 reward를 기준으로 chosen(고득점)" vs "rejected(저득점)를 구성해 학습한다. 반면, DivPO는 다음과 같은 방식을 도입했다:
- 첫 번째로, 동일한 reward 수준을 만족하거나 그 근처에 있는 "많이 쓰이지 않은(즉, 더 다양한)" 응답을 chosen으로 선택한다.
- 두 번째로, reward가 낮지만 너무 자주 쓰이는(즉, 덜 다양한) 응답을 rejected로 고른다.
즉, 단순히 최고 점수를 chosen으로, 최저 점수를 rejected로 잡는 대신, 퀄리티 임계값을 넘는 응답 후보 중에 가장 diverse한 것을 chosen으로, 임계값을 밑도는 응답 후보 중에서 가장 적게 diverse한 것을 rejected로 구성한다. 이로써 고품질 응답만을 극단적으로 집중 학습하던 기존과 달리, quality가 충분히 높은 다양한 응답들이 모델의 확률분포에서 골고루 확률값을 갖도록 조정하는 것이다.
학습 과정 요약
아래와 같은 절차로 preference pair를 구성한다.
- 베이스 모델로부터 여러 응답을 샘플링한다.
- 각 응답의 보상(RM으로 측정)과, 정해둔 diversity 척도(예: 모델 확률값 기반, 단어 빈도 기반, LLM 판단 기반)를 측정한다.
- reward가 상위권(혹은 상위권 근처)인 것 중 가장 diverse한 응답을 chosen으로, reward가 하위권(혹은 하위권 근처)인 것 중 가장 안 diverse한 응답을 rejected로 골라, 한 쌍의 pair를 만든다.
- 이를 바탕으로 DPO식 업데이트를 하되, chosen vs rejected가 위와 같은 방식으로 선정되도록 한다.
실험 결과
1) Persona 생성
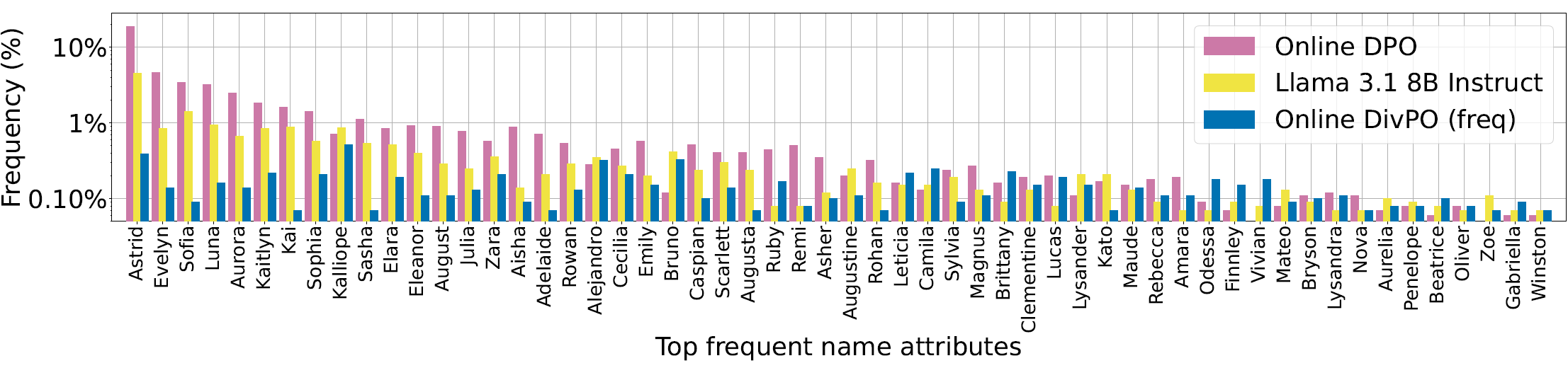
JSON 형식으로 이름, 도시, 직업을 포함한 인물을 생성하도록 하는 태스크를 통해 실험했다. 기존 DPO 방식이나 vanilla LLM 모델은 소수의 이름/직업만 반복적 생성(결과적으로 낮은 diversity)을 보였으나, DivPO는:
- JSON Validity(형식 준수도), 그리고 ArmoRM같은 품질 측정 스코어 모두 유지하거나 약간 향상
- 다만 attribute별로 더 다양한 값들을 생성

최대 45.6%까지 다양한 인물 프로필을 생성했다.
2) Keyword Stories

임의의 제목을 주고, 5개 키워드를 짧게 쓰도록 요청한 태스크다. 역시 기존 SFT, DPO 등은 동일하거나 유사한 단어들만 빈번히 반복 생성하며 전형적인 alignment collapse 현상을 보였다. 반면, DivPO는 다양한 단어를 사용한 키워드를 생성하면서도, ArmoRM 스코어(품질)를 유지하거나 소폭 향상시켰다.
3) 전체 스토리 생성
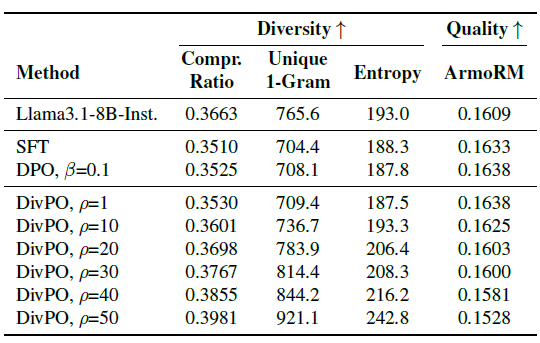
키워드 대신 직접적으로 한 문단짜리 스토리를 생성하도록 확장했다. DivPO는 스토리 내부에 나오는 단어 빈도나 표현 측면에서도 분포가 한정적이지 않고 더욱 다양하게 분산되었다. 동시에, 기존 방법 대비 스토리 품질(ArmoRM 측정)도 비슷했다.
결론 및 의의
DivPO는 인간 선호에 맞춘 모델 최적화 절차에서, 응답 품질을 유지하며 동시에 다양성을 높이는 간단하면서도 효과적인 방법이다. 어떤 방식의 diversity 척도를 사용하든, 또 offline/online 학습 설정 어느 쪽이든지 간에, DivPO는 collapse를 방지하면서 고퀄리티 분포를 얻을 수 있음을 보였다.
앞으로는 더 복잡한 응답이나 다양한 도메인(대화, 코딩 등)에 적용해, 어떻게 diversity를 측정하고 반영할지 연구가 필요하다. 그러나 DivPO 자체는 기존 preference optimization 파이프라인에 간단히 연결 가능하므로, 모델이 한 가지 정형화된 답만 내놓는 문제를 상당 부분 완화할 수 있을 것으로 보인다.



