"Probability theory is nothing but common sense reduced to calculation."
Pierre-Simon Laplace, Théorie Analytique des Probabilités (1812)
앞선 두 장에서 우리는 Diffusion Model의 핵심 아이디어인 "노이즈를 점진적으로 더하고, 그 과정을 역으로 추적하여 이미지를 생성한다"를 직관적으로 이해했습니다. 이제 이 아이디어를 수학적으로 정밀하게 표현할 차례입니다. 이번 장에서는 Diffusion Model의 수학적 기초를 이루는 세 가지 핵심 개념 가우시안 분포, 마르코프 체인, 베이즈 정리를 체계적으로 다룹니다. 나아가 이들을 활용하여 KL Divergence와 Evidence Lower Bound(ELBO)를 이해하고, 이것이 어떻게 Diffusion Model의 학습 목표로 연결되는지 살펴봅니다.
3.1 왜 확률론인가
Diffusion Model은 본질적으로 확률적 생성 모델(probabilistic generative model)입니다. 우리가 원하는 것은 훈련 데이터의 분포 $p_{\text{data}}(x)$를 학습하여, 이 분포에서 새로운 샘플을 생성하는 것입니다. 이 목표를 달성하기 위해 Diffusion Model은 다음과 같은 확률론적 구조를 사용합니다.
Forward Process에서는 원본 데이터에 가우시안 노이즈를 점진적으로 주입합니다. 이 과정은 마르코프 체인으로 모델링되며, 각 전이는 조건부 가우시안 분포를 따릅니다. Reverse Process에서는 베이즈 정리를 통해 역방향 조건부 분포를 유도하고, 신경망이 이를 근사하도록 학습합니다. 학습 목표는 KL Divergence를 최소화하는 것으로 정의되며, 이는 ELBO를 최대화하는 것과 동치입니다.
이 모든 개념들이 하나의 일관된 프레임워크 안에서 조화롭게 작동합니다. 각 개념을 깊이 이해하면, DDPM 논문의 수학적 전개가 자연스럽게 따라올 것입니다.
3.2 가우시안 분포: Diffusion의 언어
가우시안 분포(Gaussian distribution), 또는 정규분포(normal distribution)는 Diffusion Model에서 가장 핵심적인 역할을 담당합니다. Forward Process의 노이즈 주입, Reverse Process의 분포 근사, 그리고 학습 목표의 정의까지—모든 곳에서 가우시안이 등장합니다. 이 절에서는 가우시안 분포의 본질적 성질들을 탐구합니다.
3.2.1 일변량 가우시안 분포
평균 $\mu$와 분산 $\sigma^2$을 가지는 일변량 가우시안 분포의 확률밀도함수(probability density function)는 다음과 같이 정의됩니다:
$$ \mathcal{N}(x; \mu, \sigma^2) = \frac{1}{\sqrt{2\pi\sigma^2}} \exp\left(-\frac{(x-\mu)^2}{2\sigma^2}\right) $$
확률변수 $X$가 이 분포를 따를 때, $X \sim \mathcal{N}(\mu, \sigma^2)$로 표기합니다. 특히 $\mu = 0$이고 $\sigma^2 = 1$인 경우를 표준 정규분포(standard normal distribution)라 하며, $\mathcal{N}(0, 1)$로 표기합니다.
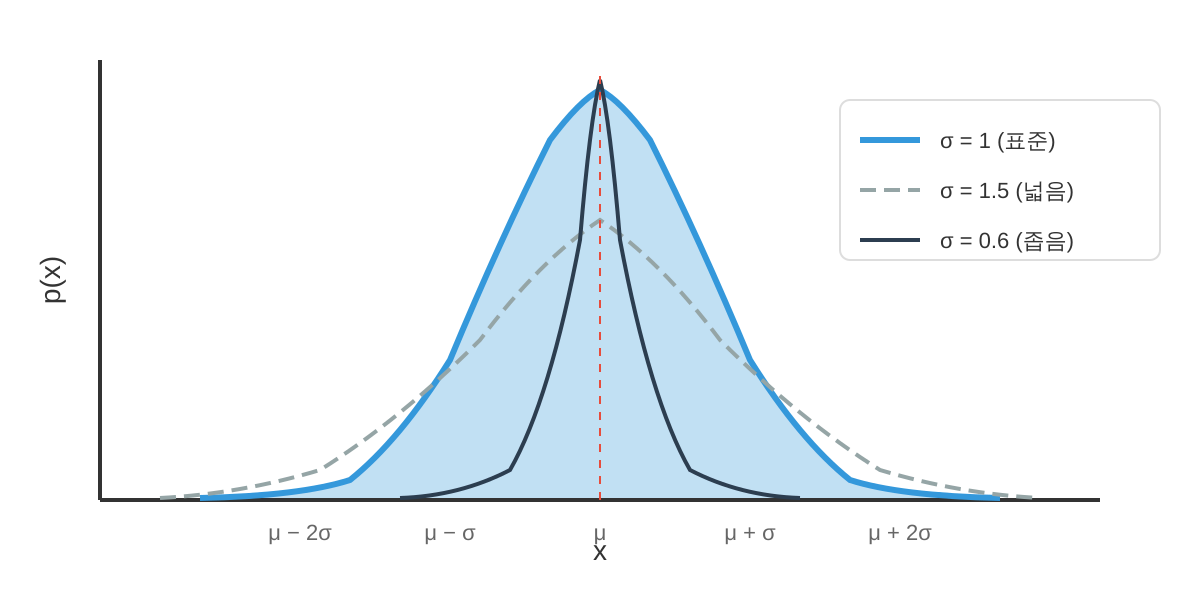
가우시안 분포의 형태는 지수 함수 내부의 이차 형식(quadratic form)에 의해 결정됩니다. $(x - \mu)^2$ 항은 $x$가 평균 $\mu$에서 멀어질수록 확률밀도가 지수적으로 감소함을 의미합니다. 분산 $\sigma^2$은 이 감소의 속도를 조절합니다—분산이 클수록 분포가 더 넓게 퍼지고, 작을수록 평균 주위에 집중됩니다.
3.2.2 다변량 가우시안 분포
실제 이미지 데이터는 수천에서 수백만 개의 픽셀을 가지므로, 고차원 공간에서의 확률분포가 필요합니다. $d$차원 공간에서의 다변량 가우시안 분포는 다음과 같이 정의됩니다:
$$ \mathcal{N}(\mathbf{x}; \boldsymbol{\mu}, \boldsymbol{\Sigma}) = \frac{1}{(2\pi)^{d/2}|\boldsymbol{\Sigma}|^{1/2}} \exp\left(-\frac{1}{2}(\mathbf{x}-\boldsymbol{\mu})^\top \boldsymbol{\Sigma}^{-1} (\mathbf{x}-\boldsymbol{\mu})\right) $$
여기서 $\boldsymbol{\mu} \in \mathbb{R}^d$는 평균 벡터이고, $\boldsymbol{\Sigma} \in \mathbb{R}^{d \times d}$는 공분산 행렬(covariance matrix)입니다. $|\boldsymbol{\Sigma}|$는 공분산 행렬의 행렬식(determinant)을 나타냅니다.
Diffusion Model에서는 주로 등방성 가우시안(isotropic Gaussian)을 사용합니다. 이는 공분산 행렬이 $\boldsymbol{\Sigma} = \sigma^2 \mathbf{I}$의 형태를 가지는 경우로, 모든 차원에서 동일한 분산을 가지며 차원 간 상관관계가 없습니다:
$$ \mathcal{N}(\mathbf{x}; \boldsymbol{\mu}, \sigma^2\mathbf{I}) = \frac{1}{(2\pi\sigma^2)^{d/2}} \exp\left(-\frac{\|\mathbf{x}-\boldsymbol{\mu}\|^2}{2\sigma^2}\right) $$
등방성 가우시안을 사용하면 계산이 크게 단순화됩니다. 공분산 행렬의 역행렬이나 행렬식을 계산할 필요 없이, 단순히 유클리드 거리의 제곱 $\|\mathbf{x}-\boldsymbol{\mu}\|^2$만 계산하면 됩니다.
3.2.3 가우시안의 핵심 성질들
가우시안 분포가 Diffusion Model에서 선택된 이유는 다음의 강력한 수학적 성질들 때문입니다.
성질 1. 선형 변환에 대한 폐쇄성: 확률변수 $X \sim \mathcal{N}(\mu, \sigma^2)$에 대해 선형 변환 $Y = aX + b$를 적용하면 $Y \sim \mathcal{N}(a\mu + b, a^2\sigma^2)$입니다. Forward Process에서 노이즈를 추가하는 $x_t = \sqrt{1-\beta_t} x_{t-1} + \sqrt{\beta_t} \epsilon$이 바로 이 형태입니다.
성질 2. 독립 가우시안의 합: $X \sim \mathcal{N}(\mu_1, \sigma_1^2)$와 $Y \sim \mathcal{N}(\mu_2, \sigma_2^2)$가 독립이면 $X + Y \sim \mathcal{N}(\mu_1 + \mu_2, \sigma_1^2 + \sigma_2^2)$입니다. 이 성질로 $x_0$에서 임의의 $x_t$로 직접 점프하는 공식을 유도할 수 있습니다.
성질 3. 조건부 가우시안: 결합 가우시안 분포에서 일부 변수가 관측되었을 때, 나머지 변수의 조건부 분포도 가우시안입니다. 이 성질은 $q(x_{t-1}|x_t, x_0)$를 해석적으로 유도하는 데 핵심적입니다.
성질 4. KL Divergence의 해석적 계산: 두 가우시안 사이의 KL Divergence는 닫힌 형태로 계산 가능합니다.
이 네 가지 성질이 결합되어 Diffusion Model의 모든 계산이 해석적으로 다루기 쉬워집니다(tractable).
3.2.4 재매개변수화 트릭
가우시안 분포에서 샘플을 생성하는 두 가지 동등한 방법이 있습니다. 직접 $x \sim \mathcal{N}(\mu, \sigma^2)$에서 샘플링하거나, 표준 정규분포에서 $\epsilon \sim \mathcal{N}(0, 1)$을 샘플링한 후 $x = \mu + \sigma \epsilon$으로 변환하는 것입니다.

두 방법은 수학적으로 완전히 동일한 분포를 생성하지만, 방법 2는 중요한 이점을 가집니다—$x$가 $\mu$와 $\sigma$에 대해 미분 가능해집니다. 이것이 VAE와 DDPM의 학습을 가능하게 하는 핵심 기법입니다.
3.3 마르코프 체인: 과거를 잊는 과정
마르코프 체인(Markov chain)은 "미래는 현재에만 의존하고 과거와는 독립"이라는 성질을 가지는 확률 과정입니다. Diffusion Model의 Forward Process와 Reverse Process 모두 이 마르코프 구조를 따르며, 이 구조 덕분에 복잡한 결합분포를 단순한 조건부 분포의 곱으로 분해할 수 있습니다.
3.3.1 마르코프 성질
확률 과정 $\{X_0, X_1, \ldots, X_T\}$가 마르코프 성질(Markov property)을 만족한다는 것은 다음을 의미합니다:
$$ P(X_t | X_{t-1}, X_{t-2}, \ldots, X_0) = P(X_t | X_{t-1}) $$
즉, 시점 $t$에서의 상태는 오직 직전 시점 $t-1$의 상태에만 의존하고, 그 이전의 모든 이력과는 조건부 독립입니다.
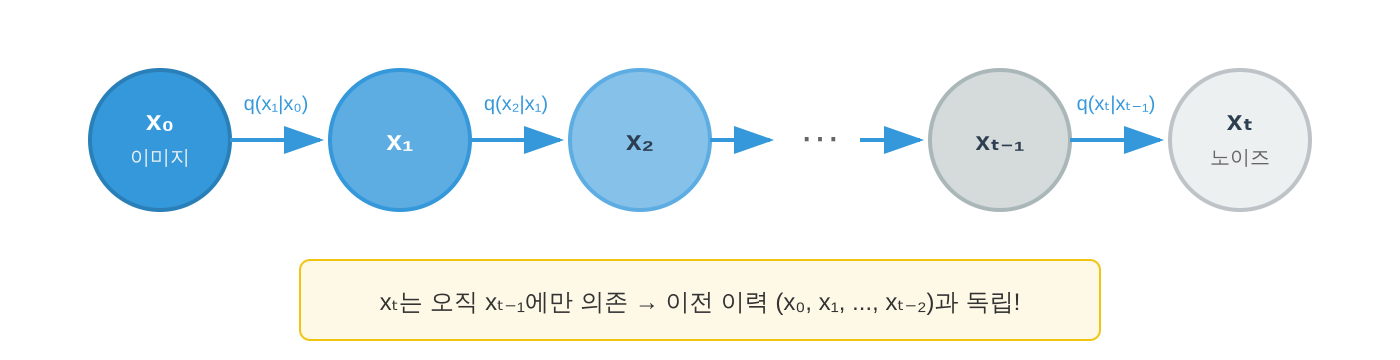
마르코프 성질의 가장 중요한 결과는 결합분포의 분해입니다:
$$ P(X_0, X_1, \ldots, X_T) = P(X_0) \prod_{t=1}^{T} P(X_t | X_{t-1}) $$
이 분해 덕분에 복잡한 $T+1$개 변수의 결합분포를 초기 분포 $P(X_0)$와 $T$개의 전이 확률(transition probability) $P(X_t | X_{t-1})$만으로 완전히 기술할 수 있습니다.
3.3.2 Forward Process의 전이 커널
Diffusion Model의 Forward Process에서 전이 커널은 가우시안입니다:
$$ q(x_t | x_{t-1}) = \mathcal{N}(x_t; \sqrt{1-\beta_t} x_{t-1}, \beta_t \mathbf{I}) $$
이 전이 커널은 두 가지 작업을 수행합니다. 이전 상태 $x_{t-1}$을 $\sqrt{1-\beta_t}$만큼 스케일링하여 신호를 약간 감쇠시키고, 분산 $\beta_t$를 가지는 가우시안 노이즈를 추가합니다.
3.3.3 임의 시점으로의 직접 도달
가우시안의 특수한 성질을 이용하면, 중간 단계를 거치지 않고 $x_0$에서 임의의 $x_t$로 직접 점프할 수 있습니다:
$$ q(x_t | x_0) = \mathcal{N}(x_t; \sqrt{\bar{\alpha}_t} x_0, (1-\bar{\alpha}_t)\mathbf{I}) $$
여기서 $\alpha_t = 1 - \beta_t$이고 $\bar{\alpha}_t = \prod_{s=1}^{t}\alpha_s$입니다.

3.3.4 시간 역전 마르코프 체인
마르코프 체인은 시간을 거꾸로 돌려도 여전히 마르코프 체인입니다. 이는 Reverse Process의 수학적 근거가 됩니다. 다만, 역방향 전이 확률 $q(x_{t-1}|x_t)$를 직접 계산하는 것은 전체 데이터 분포에 대한 지식이 필요하므로 일반적으로 계산 불가능합니다. 그러나 $x_0$가 주어지면 $q(x_{t-1}|x_t, x_0)$은 해석적으로 계산 가능하며, 이것이 DDPM 학습의 핵심이 됩니다.
3.4 베이즈 정리: 관측에서 원인으로
베이즈 정리(Bayes' theorem)는 관측된 결과로부터 그 원인을 추론하는 수학적 도구입니다. Diffusion Model에서 베이즈 정리는 Forward Process(원인에서 결과로)의 역을 구하는 데 핵심적인 역할을 합니다.
3.4.1 베이즈 정리의 구조
$$ P(A|B) = \frac{P(B|A) P(A)}{P(B)} $$
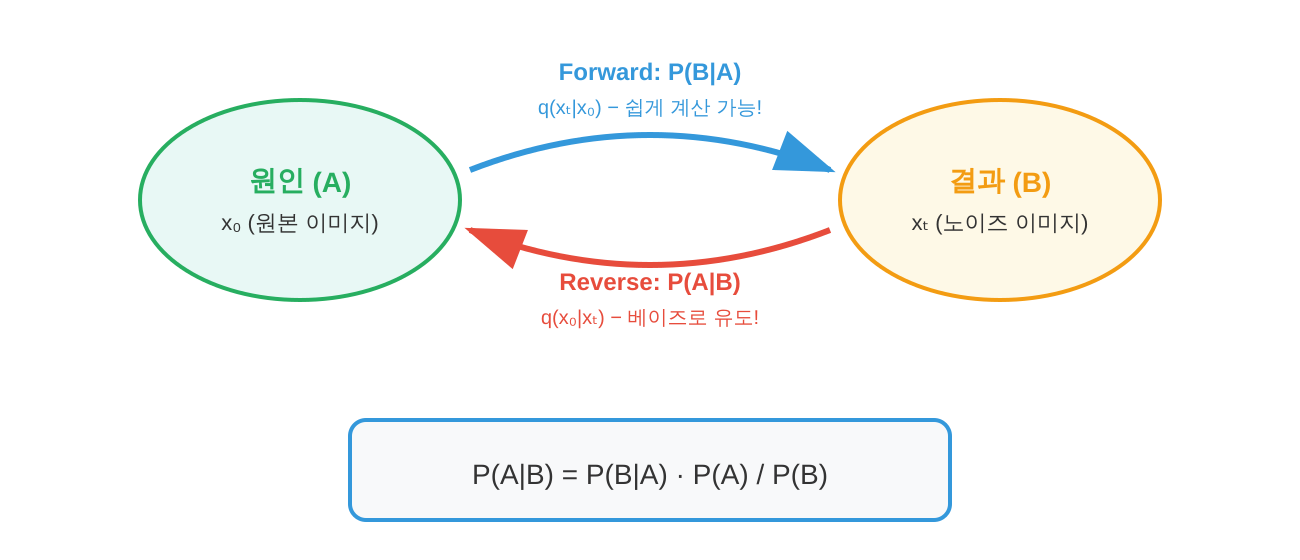
각 항의 의미를 살펴봅시다. $P(A|B)$는 사후 확률(posterior)로, $B$를 관측한 후 $A$에 대한 업데이트된 믿음입니다. $P(B|A)$는 가능도(likelihood)로, $A$가 참일 때 $B$가 관측될 확률입니다. $P(A)$는 사전 확률(prior)로, $B$를 관측하기 전 $A$에 대한 초기 믿음입니다. $P(B)$는 증거(evidence)로, 정규화 상수 역할을 합니다.
3.4.2 Diffusion에서의 베이즈 정리 적용
Diffusion Model에서 핵심적인 질문은 "$x_t$가 주어졌을 때 $x_{t-1}$의 분포는 무엇인가?"입니다. 원본 데이터 $x_0$를 조건으로 추가하면:
$$ q(x_{t-1}|x_t, x_0) = \frac{q(x_t|x_{t-1}, x_0) \cdot q(x_{t-1}|x_0)}{q(x_t|x_0)} $$
마르코프 성질에 의해 $q(x_t|x_{t-1}, x_0) = q(x_t|x_{t-1})$이고, 나머지 항들도 모두 가우시안의 닫힌 형태를 가지므로, $q(x_{t-1}|x_t, x_0)$ 역시 가우시안이 됩니다. 이것이 4장에서 다룰 DDPM 수학의 핵심입니다.
3.5 KL Divergence: 분포 간의 거리
Kullback-Leibler Divergence(KL Divergence)는 두 확률분포 간의 "차이"를 측정하는 척도입니다. Diffusion Model의 학습 목표는 본질적으로 KL Divergence를 최소화하는 것으로 표현됩니다.
3.5.1 정의와 직관
$$ D_{\text{KL}}(P \| Q) = \mathbb{E}_{x \sim P}\left[\log \frac{P(x)}{Q(x)}\right] = \int P(x) \log \frac{P(x)}{Q(x)} dx $$
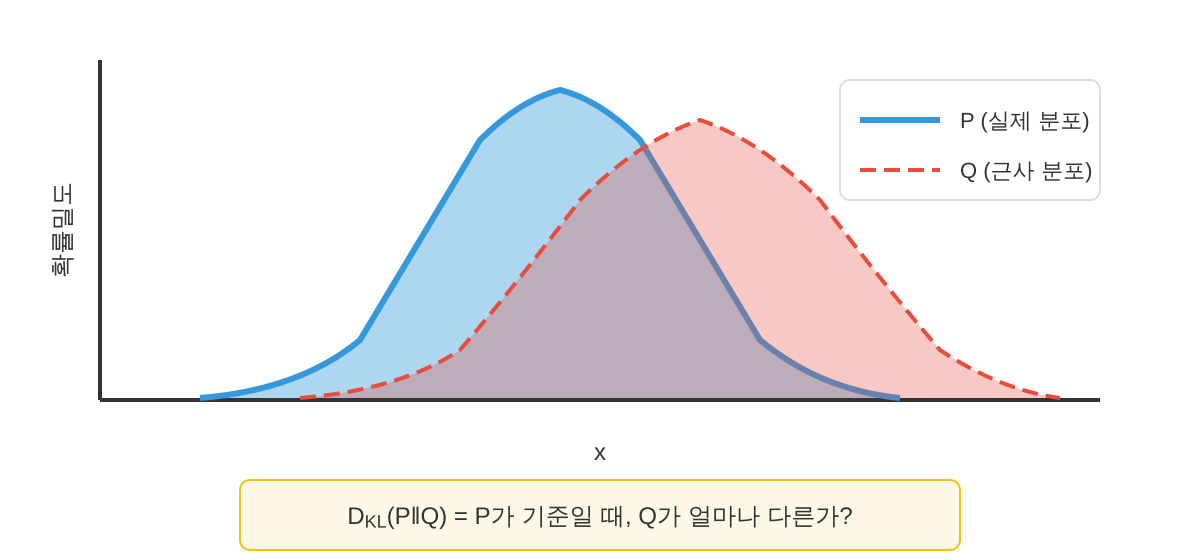
KL Divergence는 "$Q$가 실제 분포인 줄 알고 있을 때, 진짜 분포 $P$로부터 샘플이 왔을 경우의 평균적인 놀라움"으로 해석할 수 있습니다. $D_{\text{KL}}(P \| Q) = 0$이면 두 분포가 완전히 동일하고, 값이 클수록 두 분포가 더 다릅니다.
3.5.2 핵심 성질들
비음수성: $D_{\text{KL}}(P \| Q) \geq 0$이며, 등호는 $P = Q$일 때만 성립합니다 (Gibbs 부등식).
비대칭성: 일반적으로 $D_{\text{KL}}(P \| Q) \neq D_{\text{KL}}(Q \| P)$입니다. 따라서 KL Divergence는 수학적 "거리"(metric)가 아닙니다.
3.5.3 두 가우시안 분포 간의 KL Divergence
가우시안 분포 사이의 KL Divergence는 해석적으로 계산 가능합니다:
$$ D_{\text{KL}}(\mathcal{N}(\mu_1, \sigma_1^2) \| \mathcal{N}(\mu_2, \sigma_2^2)) = \log \frac{\sigma_2}{\sigma_1} + \frac{\sigma_1^2 + (\mu_1 - \mu_2)^2}{2\sigma_2^2} - \frac{1}{2} $$
이 닫힌 형태 덕분에 DDPM의 학습 목표를 효율적으로 계산할 수 있습니다.
3.6 Evidence Lower Bound: 변분 추론의 핵심
Evidence Lower Bound(ELBO)는 잠재 변수 모델의 학습에서 핵심적인 역할을 합니다. 직접 최대화하기 어려운 log-likelihood를 대신하여, 최적화 가능한 하한을 제공합니다.
3.6.1 ELBO의 도출
잠재 변수 $z$와 관측 변수 $x$가 있을 때, 우리가 최대화하고 싶은 것은 데이터의 log-likelihood $\log p(x)$입니다. 그러나 이 값은 대부분의 경우 계산 불가능합니다. Jensen 부등식을 사용하면:
$$ \log p(x) \geq \mathbb{E}_{z \sim q}\left[\log \frac{p(x, z)}{q(z)}\right] = \text{ELBO}(q) $$
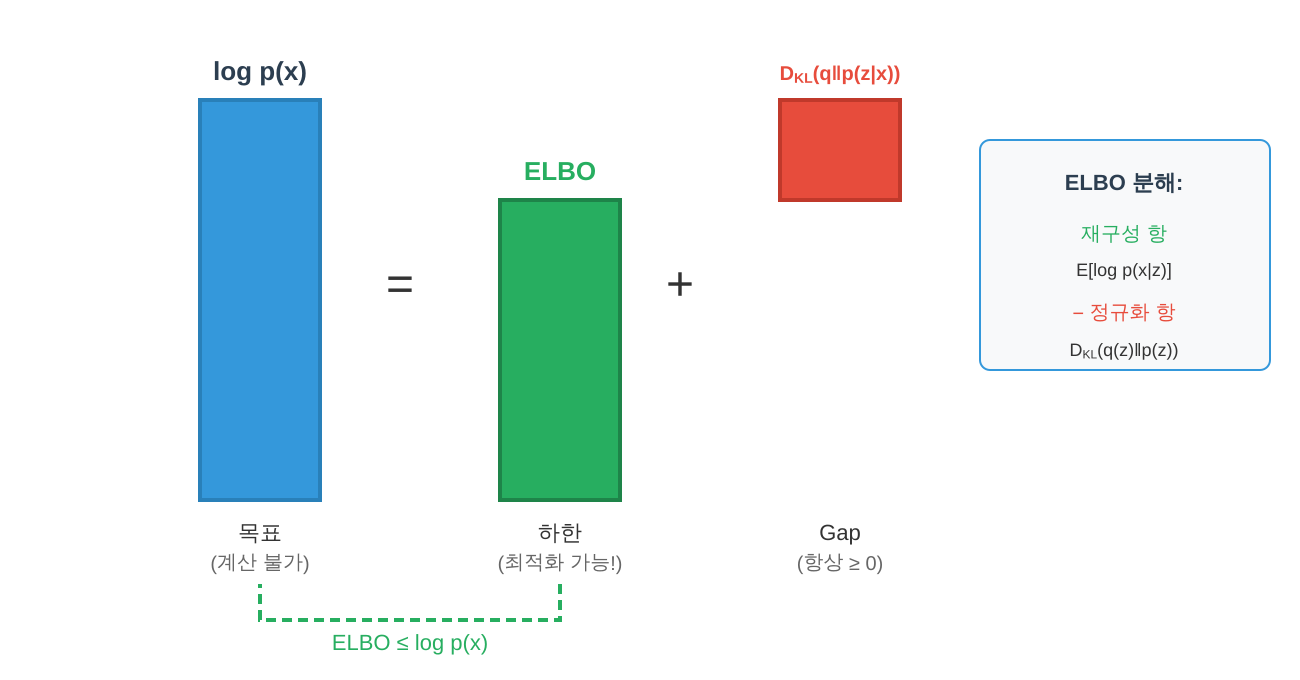
3.6.2 ELBO와 KL Divergence의 관계
$$ \log p(x) = \text{ELBO}(q) + D_{\text{KL}}(q(z) \| p(z|x)) $$
KL Divergence가 항상 비음수이므로, $\text{ELBO}(q) \leq \log p(x)$가 됩니다. $q(z) = p(z|x)$일 때 KL이 0이 되어 ELBO가 log-likelihood와 정확히 일치합니다.
3.6.3 Diffusion Model에서의 ELBO
DDPM에서 ELBO는 각 시간 단계에 대한 KL Divergence 항들의 합으로 분해됩니다:
$$ \text{ELBO} = \underbrace{\mathbb{E}_q[\log p_\theta(x_0|x_1)]}_{\text{재구성}} - \sum_{t=2}^{T} \underbrace{D_{\text{KL}}(q(x_{t-1}|x_t, x_0) \| p_\theta(x_{t-1}|x_t))}_{\text{각 단계의 근사 오차}} - \underbrace{D_{\text{KL}}(q(x_T|x_0) \| p(x_T))}_{\approx 0} $$

3.7 개념들의 통합: Diffusion의 큰 그림
이제까지 다룬 개념들이 Diffusion Model에서 어떻게 조합되는지 정리해봅시다.

3.8 요약
이번 장에서 우리는 Diffusion Model의 수학적 기초를 이루는 핵심 개념들을 체계적으로 학습했습니다.
가우시안 분포의 성질들(선형 변환, 독립 합, 조건부 분포, 재매개변수화)이 Diffusion Model의 계산적 다루기 쉬움을 보장합니다. 마르코프 체인은 복잡한 과정을 단순한 단계들의 연쇄로 분해하고, 시간 역전의 구조를 제공합니다. 베이즈 정리는 Forward Process의 역을 유도하는 핵심 도구입니다. KL Divergence는 분포 간의 차이를 측정하는 척도이며, 가우시안 간에는 해석적 형태를 가집니다. ELBO는 계산 불가능한 log-likelihood 대신 최적화할 수 있는 하한을 제공합니다.
이제 우리는 DDPM 논문을 이해하기 위한 모든 도구를 갖추었습니다. 다음 장에서는 이 도구들을 사용하여 Forward Process의 수학적 세부사항을 완전히 분석합니다. $q(x_t|x_0)$의 유도, 노이즈 스케줄의 의미, 그리고 신호 대 잡음비(Signal-to-Noise Ratio)의 관점에서 Forward Process를 깊이 이해할 것입니다.
참고문헌
- Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer. Chapter 2: Probability Distributions.
- Norris, J. R. (1997). Markov Chains. Cambridge University Press.
- Kullback, S., & Leibler, R. A. (1951). On Information and Sufficiency. The Annals of Mathematical Statistics, 22(1), 79-86.
- Kingma, D. P., & Welling, M. (2014). Auto-Encoding Variational Bayes. Proceedings of the 2nd International Conference on Learning Representations (ICLR). arXiv:1312.6114
- Ho, J., Jain, A., & Abbeel, P. (2020). Denoising Diffusion Probabilistic Models. Advances in Neural Information Processing Systems, 33, 6840-6851. arXiv:2006.11239
- Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N., & Ganguli, S. (2015). Deep Unsupervised Learning using Nonequilibrium Thermodynamics. Proceedings of the 32nd International Conference on Machine Learning. arXiv:1503.03585
- Blei, D. M., Kucukelbir, A., & McAuliffe, J. D. (2017). Variational Inference: A Review for Statisticians. Journal of the American Statistical Association, 112(518), 859-877.
'인공지능 논문 정리 > Diffusiion' 카테고리의 다른 글
| [Diffusion 6] Score Function이란 무엇인가: Score Matching에 대한 이해 (1) | 2026.01.20 |
|---|---|
| [Diffusion 5] DDPM 논문 완전 정복 (하): Reverse Process와 학습 (0) | 2026.01.19 |
| [Diffusion 4] DDPM 논문 완전 정복 (상): Forward Process (0) | 2026.01.18 |
| [Diffusion 2] Forward와 Reverse: Diffusion의 두 가지 여정 (1) | 2026.01.18 |
| [Diffusion 1] 노이즈에서 이미지로: Diffusion Model의 기본 원리 (0) | 2026.01.18 |

