"The essential idea is to systematically and slowly destroy structure in a data distribution through an iterative forward diffusion process."
Sohl-Dickstein et al., Deep Unsupervised Learning using Nonequilibrium Thermodynamics (2015)
앞선 장에서 우리는 Diffusion Model을 이해하기 위한 확률론적 기초인 가우시안 분포, 마르코프 체인, 베이즈 정리, KL Divergence, ELBO를 체계적으로 다루었습니다. 이제 이 도구들을 실제로 적용하여 DDPM(Denoising Diffusion Probabilistic Models) 논문의 수학에 대해서 알아볼 차례입니다. 이번 장에서는 Forward Process에 집중합니다. 데이터에 노이즈를 주입하는 이 과정은 언뜻 단순해 보이지만, 그 수학적 구조 안에는 우아함과 실용적 통찰이 담겨 있습니다.
4.1 Forward Process의 정의
Forward Process는 원본 데이터 $x_0$에서 시작하여 점진적으로 가우시안 노이즈를 주입하는 마르코프 체인입니다. Ho et al. (2020)의 DDPM 논문에서 정의된 형태를 따라, 이 과정을 수학적으로 정밀하게 기술해 보겠습니다.
4.1.1 단일 스텝 전이
Forward Process의 단일 스텝 전이는 다음의 조건부 가우시안 분포로 정의됩니다:
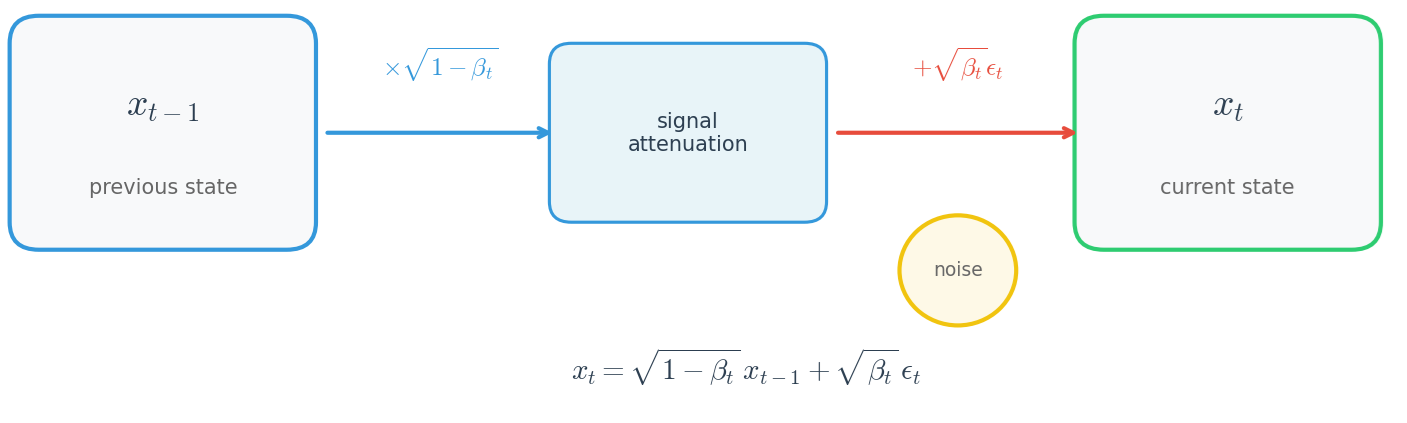
$$ q(x_t | x_{t-1}) = \mathcal{N}(x_t; \sqrt{1-\beta_t} \, x_{t-1}, \beta_t \mathbf{I}) $$
여기서 $\beta_t \in (0, 1)$는 시간 $t$에서의 노이즈 스케줄(noise schedule)입니다. 이 정의가 의미하는 바를 분해해 봅시다.
평균이 $\sqrt{1-\beta_t} \, x_{t-1}$이라는 것은 이전 상태를 $\sqrt{1-\beta_t}$만큼 스케일링한다는 뜻입니다. $\beta_t$가 작은 양수이므로 $\sqrt{1-\beta_t} < 1$이고, 따라서 신호가 약간 감쇠됩니다. 분산이 $\beta_t \mathbf{I}$라는 것은 각 차원에 독립적으로 분산 $\beta_t$를 가지는 가우시안 노이즈를 추가한다는 뜻입니다.
3장에서 배운 재매개변수화 트릭을 적용하면, 이 전이는 다음과 같이 등가적으로 표현됩니다:
$$ x_t = \sqrt{1-\beta_t} \, x_{t-1} + \sqrt{\beta_t} \, \epsilon_t, \quad \epsilon_t \sim \mathcal{N}(0, \mathbf{I}) $$
이 표현은 Forward Process의 직관적 의미를 명확히 드러냅니다. 각 스텝에서 이전 상태를 약간 축소하고($\sqrt{1-\beta_t}$), 새로운 노이즈를 추가합니다($\sqrt{\beta_t} \, \epsilon_t$). 시간이 지남에 따라 원본 신호는 점점 약해지고, 누적된 노이즈가 지배적이 됩니다.
4.1.2 마르코프 체인으로서의 Forward Process
Forward Process는 마르코프 체인이므로, 3장에서 배운 대로 결합분포가 조건부 분포의 곱으로 분해됩니다:
$$ q(x_{1:T} | x_0) = \prod_{t=1}^{T} q(x_t | x_{t-1}) $$
여기서 $x_{1:T}$는 $\{x_1, x_2, \ldots, x_T\}$를 간략히 나타내는 표기입니다. 이 분해는 Forward Process의 전체 경로를 기술합니다. 데이터 $x_0$에서 시작하여 $T$번의 노이즈 주입을 거쳐 최종 상태 $x_T$에 도달합니다.
마르코프 성질 덕분에 각 전이는 오직 직전 상태에만 의존합니다. 이는 복잡한 결합분포를 단순한 조건부 분포들의 곱으로 분해할 수 있게 해주어, 계산과 분석을 크게 단순화합니다.
4.1.3 분산 보존의 원리
Forward Process의 전이 정의에서 계수들이 $\sqrt{1-\beta_t}$와 $\sqrt{\beta_t}$로 선택된 데에는 깊은 이유가 있습니다. 이 선택은 분산 보존(variance preserving) 속성을 보장합니다.
$x_{t-1}$의 분산이 1이라고 가정합시다 (표준화된 데이터). 그러면 $x_t$의 분산은:
$$ \text{Var}(x_t) = (1-\beta_t) \cdot \text{Var}(x_{t-1}) + \beta_t \cdot \text{Var}(\epsilon_t) = (1-\beta_t) \cdot 1 + \beta_t \cdot 1 = 1 $$
즉, 각 전이에서 분산이 1로 유지됩니다. 이 속성은 학습의 안정성에 중요합니다. 만약 분산이 계속 증가하거나 감소한다면, 수치적 불안정성이 발생하거나 신경망이 다루기 어려운 스케일의 값들을 처리해야 할 것입니다.
4.2 임의 시점으로의 직접 도달
Forward Process의 가장 강력한 성질 중 하나는 $x_0$에서 임의의 $x_t$로 중간 단계를 거치지 않고 한 번에 도달할 수 있다는 것입니다. 이 closed-form 공식은 학습 과정에서 매우 중요한 역할을 합니다.
4.2.1 누적 계수의 정의
먼저 표기의 편의를 위해 새로운 변수들을 정의합니다:
$$ \alpha_t := 1 - \beta_t $$ $$ \bar{\alpha}_t := \prod_{s=1}^{t} \alpha_s = \prod_{s=1}^{t} (1-\beta_s) $$
$\alpha_t$는 단일 스텝에서 신호가 보존되는 비율입니다. $\bar{\alpha}_t$는 시점 0부터 $t$까지의 누적 보존 비율로, 각 스텝의 보존 비율을 모두 곱한 값입니다. $\beta_t$가 양수이므로 $\alpha_t < 1$이고, 따라서 $\bar{\alpha}_t$는 $t$가 증가함에 따라 단조 감소합니다.

4.2.2 Closed-Form 공식의 유도
이제 $q(x_t | x_0)$의 closed-form을 유도합니다. 재매개변수화를 사용한 전이 공식을 연속적으로 적용해 봅시다.
$t=1$인 경우:
$$ x_1 = \sqrt{\alpha_1} \, x_0 + \sqrt{1-\alpha_1} \, \epsilon_1 $$
$t=2$인 경우:
$$ x_2 = \sqrt{\alpha_2} \, x_1 + \sqrt{1-\alpha_2} \, \epsilon_2 = \sqrt{\alpha_2} \left( \sqrt{\alpha_1} \, x_0 + \sqrt{1-\alpha_1} \, \epsilon_1 \right) + \sqrt{1-\alpha_2} \, \epsilon_2 $$ $$ = \sqrt{\alpha_1 \alpha_2} \, x_0 + \sqrt{\alpha_2(1-\alpha_1)} \, \epsilon_1 + \sqrt{1-\alpha_2} \, \epsilon_2 $$
여기서 $\sqrt{\alpha_2(1-\alpha_1)} \, \epsilon_1 + \sqrt{1-\alpha_2} \, \epsilon_2$는 두 개의 독립적인 가우시안의 선형 결합입니다. 3장에서 배운 대로, 독립 가우시안의 합은 다시 가우시안이며, 그 분산은 각 분산의 합입니다:
$$ \text{Var}\left(\sqrt{\alpha_2(1-\alpha_1)} \, \epsilon_1 + \sqrt{1-\alpha_2} \, \epsilon_2\right) = \alpha_2(1-\alpha_1) + (1-\alpha_2) = 1 - \alpha_1 \alpha_2 $$
따라서:
$$ x_2 = \sqrt{\alpha_1 \alpha_2} \, x_0 + \sqrt{1 - \alpha_1 \alpha_2} \, \bar{\epsilon} $$
여기서 $\bar{\epsilon} \sim \mathcal{N}(0, \mathbf{I})$입니다. 이 패턴을 일반화하면:
$$ x_t = \sqrt{\bar{\alpha}_t} \, x_0 + \sqrt{1 - \bar{\alpha}_t} \, \epsilon, \quad \epsilon \sim \mathcal{N}(0, \mathbf{I}) $$
이를 조건부 분포의 형태로 쓰면:
$$ q(x_t | x_0) = \mathcal{N}(x_t; \sqrt{\bar{\alpha}_t} \, x_0, (1-\bar{\alpha}_t) \mathbf{I}) $$
4.2.3 Closed-Form의 의의
이 closed-form 공식은 실용적으로 매우 중요합니다. 학습 과정에서 $t$를 무작위로 샘플링하고, 해당 시점의 $x_t$를 생성해야 합니다. 만약 closed-form이 없다면, $x_0$에서 시작하여 $t$번의 순차적 전이를 수행해야 할 것입니다. 이는 $T=1000$인 경우 각 학습 샘플마다 1000번의 연산이 필요함을 의미합니다.
그러나 closed-form 덕분에 단 한 번의 연산으로 임의의 $x_t$를 샘플링할 수 있습니다:
$$ x_t = \sqrt{\bar{\alpha}_t} \, x_0 + \sqrt{1 - \bar{\alpha}_t} \, \epsilon $$
이것이 바로 가우시안 분포의 선형 변환에 대한 닫힘 성질이 주는 계산적 이점입니다.

4.3 노이즈 스케줄의 설계
노이즈 스케줄 $\{\beta_t\}_{t=1}^{T}$는 Forward Process의 동작을 결정하는 핵심 하이퍼파라미터입니다. 스케줄의 선택은 모델의 성능에 상당한 영향을 미칩니다.
4.3.1 선형 스케줄
Ho et al. (2020)의 원본 DDPM 논문에서는 선형 스케줄(linear schedule)을 사용했습니다:
$$ \beta_t = \beta_1 + \frac{t-1}{T-1}(\beta_T - \beta_1) $$
논문에서 사용한 구체적인 값은 $\beta_1 = 10^{-4}$, $\beta_T = 0.02$, $T = 1000$입니다. 이 스케줄에서 $\beta_t$는 시간에 따라 선형적으로 증가합니다. 초기에는 작은 노이즈가 추가되고, 시간이 지남에 따라 노이즈의 양이 점차 증가합니다.
4.3.2 코사인 스케줄
Nichol과 Dhariwal (2021)은 선형 스케줄의 한계를 지적했습니다. 선형 스케줄에서는 Forward Process 후반부에서 이미지가 너무 빠르게 순수한 노이즈로 변해버립니다. 이는 특히 저해상도 이미지에서 문제가 됩니다.
이를 해결하기 위해 코사인 스케줄(cosine schedule)이 제안되었습니다. 코사인 스케줄은 $\bar{\alpha}_t$를 직접 정의합니다:
$$ \bar{\alpha}_t = \frac{f(t)}{f(0)}, \quad f(t) = \cos\left(\frac{t/T + s}{1 + s} \cdot \frac{\pi}{2}\right)^2 $$
여기서 $s = 0.008$은 작은 오프셋으로, $t=0$ 근처에서 $\beta_t$가 너무 작아지는 것을 방지합니다. 이 스케줄에서 $\beta_t$는 다음과 같이 역산됩니다:
$$ \beta_t = 1 - \frac{\bar{\alpha}_t}{\bar{\alpha}_{t-1}} $$

4.3.3 스케줄 설계의 원칙
좋은 노이즈 스케줄은 다음 조건들을 만족해야 합니다.
첫째, 충분한 노이즈 주입입니다. $T$ 스텝 후에 $x_T$의 분포가 표준 가우시안에 충분히 가까워야 합니다. 이는 $\bar{\alpha}_T \approx 0$을 의미합니다.
둘째, 점진적 파괴입니다. 각 스텝에서의 변화가 너무 급격하지 않아야 합니다. 이는 신경망이 역과정을 학습하기 쉽게 만듭니다.
셋째, 균등한 학습 기여입니다. 모든 시간 스텝이 학습에 비슷하게 기여해야 합니다. 만약 특정 시간대의 데이터가 너무 쉽거나 너무 어려우면 학습이 비효율적이 됩니다.
4.4 Signal-to-Noise Ratio 관점
Forward Process를 이해하는 또 다른 강력한 관점은 Signal-to-Noise Ratio(SNR)입니다. 이 관점에서 $x_t$를 신호와 노이즈의 혼합으로 해석합니다.
4.4.1 SNR의 정의
$q(x_t|x_0)$의 closed-form을 다시 살펴봅시다:
$$ x_t = \sqrt{\bar{\alpha}_t} \, x_0 + \sqrt{1-\bar{\alpha}_t} \, \epsilon $$
이 표현에서 $\sqrt{\bar{\alpha}_t} \, x_0$는 신호(signal) 성분이고, $\sqrt{1-\bar{\alpha}_t} \, \epsilon$는 노이즈(noise) 성분입니다. SNR은 신호의 세기와 노이즈의 세기의 비율로 정의됩니다:
$$ \text{SNR}(t) = \frac{\text{신호의 분산}}{\text{노이즈의 분산}} = \frac{\bar{\alpha}_t}{1 - \bar{\alpha}_t} $$
4.4.2 SNR의 변화
$t=0$에서는 $\bar{\alpha}_0 = 1$이므로 $\text{SNR}(0) = \infty$입니다 (순수한 신호). $t$가 증가함에 따라 $\bar{\alpha}_t$가 감소하고, SNR도 감소합니다. $t=T$에서는 $\bar{\alpha}_T \approx 0$이므로 $\text{SNR}(T) \approx 0$입니다 (거의 순수한 노이즈).
로그 스케일에서 SNR을 보면:
$$ \log \text{SNR}(t) = \log \bar{\alpha}_t - \log(1-\bar{\alpha}_t) $$
이 양은 $+\infty$에서 $-\infty$로 단조 감소합니다.

4.4.3 SNR과 학습의 관계
SNR 관점은 Reverse Process 학습의 난이도를 이해하는 데 도움이 됩니다.
높은 SNR (작은 $t$)의 경우, 신호가 강하게 남아 있으므로 노이즈를 예측하기 상대적으로 쉽습니다. 그러나 노이즈의 양이 작아 정확한 예측이 필요합니다.
낮은 SNR (큰 $t$)의 경우, 신호가 거의 없으므로 노이즈 예측의 절대적 정확도는 덜 중요합니다. 그러나 희미한 신호에서 의미 있는 정보를 추출해야 합니다.
중간 SNR의 경우, 신호와 노이즈가 비슷한 세기를 가지며, 이 영역에서의 학습이 가장 도전적이면서도 중요합니다.
4.5 Forward Process의 한계 분포
Forward Process의 중요한 성질 중 하나는 충분히 많은 스텝 후에 도달하는 한계 분포(limiting distribution)입니다.
4.5.1 표준 가우시안으로의 수렴
$T$가 충분히 크고 노이즈 스케줄이 적절히 설계되면, $\bar{\alpha}_T \approx 0$이 됩니다. 이 경우:
$$ q(x_T | x_0) = \mathcal{N}(x_T; \sqrt{\bar{\alpha}_T} \, x_0, (1-\bar{\alpha}_T) \mathbf{I}) \approx \mathcal{N}(x_T; 0, \mathbf{I}) $$
즉, $x_T$의 분포는 원본 데이터 $x_0$와 거의 독립적인 표준 가우시안에 수렴합니다. 이것이 Forward Process가 "데이터의 구조를 완전히 파괴한다"는 의미입니다.
4.5.2 데이터 분포에 대한 평균
$x_0$가 데이터 분포 $q(x_0)$를 따를 때, $x_T$의 주변 분포는:
$$ q(x_T) = \int q(x_T | x_0) q(x_0) \, dx_0 \approx \mathcal{N}(0, \mathbf{I}) $$
모든 데이터 포인트가 동일한 가우시안 노이즈 분포로 수렴하므로, $x_T$만 보고는 원본 $x_0$에 대한 정보를 거의 얻을 수 없습니다. 이것이 바로 Reverse Process가 필요한 이유입니다. $x_T$에서 시작하여 점진적으로 정보를 복원해 나가야 합니다.

4.6 학습에서의 활용
Forward Process의 수학적 구조가 실제 학습 과정에서 어떻게 활용되는지 살펴봅시다.
4.6.1 학습 데이터 생성
DDPM의 학습은 다음 과정을 반복합니다:
1. 데이터셋에서 $x_0$를 샘플링합니다.
2. 균등 분포에서 시간 스텝 $t \sim \text{Uniform}(\{1, \ldots, T\})$를 샘플링합니다.
3. 표준 가우시안에서 $\epsilon \sim \mathcal{N}(0, \mathbf{I})$를 샘플링합니다.
4. Closed-form을 사용하여 $x_t = \sqrt{\bar{\alpha}_t} \, x_0 + \sqrt{1-\bar{\alpha}_t} \, \epsilon$를 계산합니다.
5. 신경망 $\epsilon_\theta(x_t, t)$가 $\epsilon$을 예측하도록 학습합니다.
여기서 핵심은 4단계입니다. Closed-form 덕분에 임의의 $t$에 대한 학습 샘플을 효율적으로 생성할 수 있습니다.
4.6.2 손실 함수의 형태
DDPM의 단순화된 손실 함수는 다음과 같습니다:
$$ L_{\text{simple}} = \mathbb{E}_{t, x_0, \epsilon}\left[ \| \epsilon - \epsilon_\theta(x_t, t) \|^2 \right] $$
이 손실 함수의 의미는 명확합니다. 신경망에게 노이즈가 섞인 이미지 $x_t$와 시간 정보 $t$가 주어지면, 그 이미지에 추가된 노이즈 $\epsilon$을 예측하라는 것입니다. 이것이 왜 의미 있는지, 그리고 이것이 어떻게 Reverse Process의 학습과 연결되는지는 5장에서 자세히 다룹니다.
4.7 요약
이번 장에서 우리는 DDPM의 Forward Process를 수학적으로 완전히 이해했습니다.
Forward Process는 마르코프 체인으로 모델링되며, 각 전이는 조건부 가우시안 $q(x_t|x_{t-1}) = \mathcal{N}(x_t; \sqrt{\alpha_t}x_{t-1}, (1-\alpha_t)\mathbf{I})$를 따릅니다. 가우시안의 특수한 성질 덕분에 임의 시점으로의 직접 도달이 가능합니다: $q(x_t|x_0) = \mathcal{N}(x_t; \sqrt{\bar{\alpha}_t}x_0, (1-\bar{\alpha}_t)\mathbf{I})$. 노이즈 스케줄의 설계는 모델 성능에 중요하며, 선형 스케줄과 코사인 스케줄이 대표적입니다. SNR 관점에서 Forward Process는 신호 대 노이즈 비율을 무한대에서 0으로 점진적으로 감소시킵니다. 충분한 스텝 후에 $x_T$의 분포는 표준 가우시안에 수렴합니다.
참고문헌
- Ho, J., Jain, A., & Abbeel, P. (2020). Denoising Diffusion Probabilistic Models. Advances in Neural Information Processing Systems, 33, 6840-6851. arXiv:2006.11239
- Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N., & Ganguli, S. (2015). Deep Unsupervised Learning using Nonequilibrium Thermodynamics. Proceedings of the 32nd International Conference on Machine Learning (ICML), 2256-2265. arXiv:1503.03585
- Nichol, A., & Dhariwal, P. (2021). Improved Denoising Diffusion Probabilistic Models. Proceedings of the 38th International Conference on Machine Learning (ICML), 8162-8171. arXiv:2102.09672
- Kingma, D. P., & Welling, M. (2014). Auto-Encoding Variational Bayes. Proceedings of the 2nd International Conference on Learning Representations (ICLR). arXiv:1312.6114
'인공지능 논문 정리 > Diffusiion' 카테고리의 다른 글
| [Diffusion 6] Score Function이란 무엇인가: Score Matching에 대한 이해 (1) | 2026.01.20 |
|---|---|
| [Diffusion 5] DDPM 논문 완전 정복 (하): Reverse Process와 학습 (0) | 2026.01.19 |
| [Diffusion 3] Diffusion을 위한 확률론: 가우시안, 마르코프 체인, 그리고 베이즈 (0) | 2026.01.18 |
| [Diffusion 2] Forward와 Reverse: Diffusion의 두 가지 여정 (1) | 2026.01.18 |
| [Diffusion 1] 노이즈에서 이미지로: Diffusion Model의 기본 원리 (0) | 2026.01.18 |


