"The score function is a vector field that points in the direction of increasing log probability density."
Yang Song, Generative Modeling by Estimating Gradients of the Data Distribution (2019)
5장에서 우리는 DDPM의 학습 목표가 결국 노이즈 예측 문제로 귀결된다는 것을 보았습니다. 그리고 마지막 부분에서 이 노이즈 예측이 Denoising Score Matching과 수학적으로 동치라는 사실을 언급했습니다. 이번 장에서는 이 연결고리의 핵심에 있는 개념인 Score Function을 깊이 탐구합니다. Score Function이란 무엇이며, 왜 이것을 학습하는 것이 생성 모델링에서 강력한 접근법이 되는지 살펴봅니다. 나아가 Score Matching의 다양한 변형들을 체계적으로 정리하고, DDPM과 Score-based Generative Models이 어떻게 통합적 관점에서 이해될 수 있는지 보여줍니다.
6.1 Score Function의 정의
확률 분포 $p(x)$가 주어졌을 때, Score Function(또는 Stein Score)은 로그 확률 밀도 함수의 그래디언트로 정의됩니다:
$$ s(x) = \nabla_x \log p(x) $$
여기서 $\nabla_x$는 데이터 $x$에 대한 그래디언트 연산자입니다. 이 정의는 단순해 보이지만, 그 안에는 깊은 의미가 담겨 있습니다.
6.1.1 중요한 구분: 두 종류의 Score
통계학에서 score라는 용어는 두 가지 다른 의미로 사용되므로 주의가 필요합니다.
첫째, Fisher Score는 로그 우도 함수를 파라미터 $\theta$에 대해 미분한 것입니다:
$$ \nabla_\theta \log p(x; \theta) $$
이는 최대 우도 추정(MLE)에서 핵심적인 역할을 합니다. 둘째, Stein Score(또는 data score)는 로그 확률 밀도를 데이터 $x$에 대해 미분한 것입니다:
$$ \nabla_x \log p(x) $$
Score-based generative models에서 "score"라고 할 때는 항상 후자를 의미합니다. 이 장에서도 Score Function이라 하면 Stein Score를 지칭합니다.
6.1.2 Score Function의 기하학적 의미
Score Function $s(x) = \nabla_x \log p(x)$는 각 점 $x$에서 로그 확률 밀도가 가장 빠르게 증가하는 방향을 가리키는 벡터입니다. 다시 말해, 이 벡터장(vector field)을 따라가면 확률 밀도가 높은 영역으로 이동하게 됩니다.
직관적으로, Score Function은 "데이터가 어디에 있는가"를 가리키는 화살표라고 생각할 수 있습니다. 데이터 분포의 모드(mode) 근처에서는 Score가 0에 가까워지고, 모드에서 멀어질수록 Score의 크기가 커지며 모드 방향을 가리킵니다.
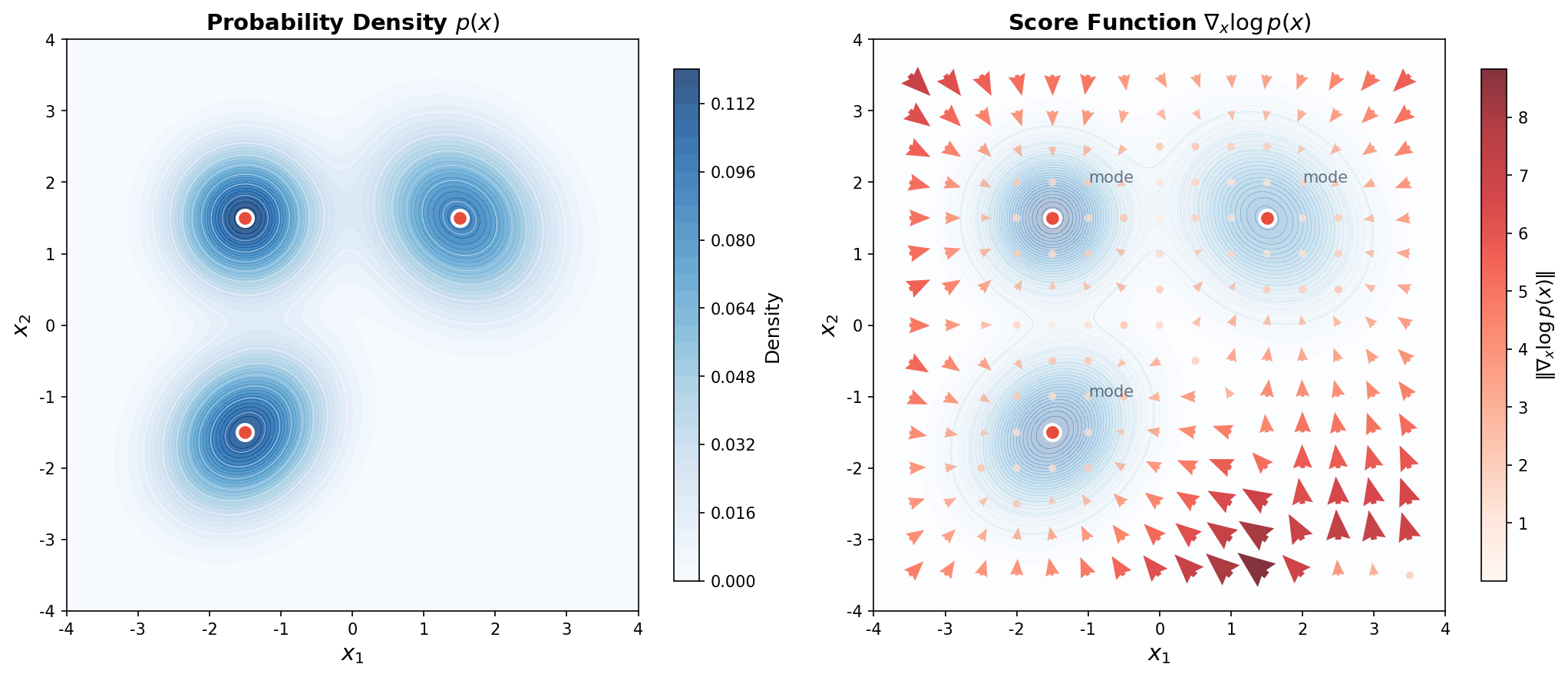
6.1.3 Score Function의 핵심 특성
Score Function이 생성 모델링에서 특별한 이유는 정규화 상수에 독립적이라는 점입니다. 확률 분포가 다음과 같이 정규화되지 않은 형태로 주어진다고 합시다:
$$ p(x) = \frac{1}{Z} \tilde{p}(x) $$
여기서 $Z = \int \tilde{p}(x) dx$는 정규화 상수입니다. 이때 Score Function을 계산하면:
$$ \nabla_x \log p(x) = \nabla_x \log \tilde{p}(x) - \nabla_x \log Z = \nabla_x \log \tilde{p}(x) $$
정규화 상수 $Z$는 $x$에 의존하지 않으므로 그래디언트가 0이 됩니다. 따라서 Score Function은 $\tilde{p}(x)$만 알면 계산할 수 있으며, 계산이 어려운 $Z$를 알 필요가 없습니다.
6.2 Score Matching: 기본 아이디어
Score Function을 직접 계산하려면 진짜 데이터 분포 $p_{\text{data}}(x)$를 알아야 합니다. 하지만 우리에게 주어진 것은 데이터 샘플뿐이며, 실제 분포는 알 수 없습니다. Score Matching은 이 문제를 해결하는 기법으로, 신경망 $s_\theta(x)$를 학습하여 진짜 Score Function $\nabla_x \log p_{\text{data}}(x)$를 근사하도록 합니다.
6.2.1 Fisher Divergence
Score Matching의 목표는 모델의 Score $s_\theta(x)$와 데이터의 Score $\nabla_x \log p_{\text{data}}(x)$ 사이의 거리를 최소화하는 것입니다. 이 거리를 측정하는 자연스러운 방법은 Fisher Divergence(또는 Expected Squared Score Difference)입니다:
$$ J(\theta) = \frac{1}{2} \mathbb{E}_{p_{\text{data}}(x)} \left[ \| s_\theta(x) - \nabla_x \log p_{\text{data}}(x) \|^2 \right] $$
이 목적함수를 최소화하면 모델의 Score가 데이터의 Score와 일치하게 됩니다. 그러나 여기에 명백한 문제가 있습니다. $\nabla_x \log p_{\text{data}}(x)$를 모르기 때문에 이 목적함수를 직접 계산할 수 없습니다.
6.2.2 Explicit Score Matching
Hyvärinen (2005)의 핵심 기여는 Fisher Divergence를 데이터의 Score를 알지 못해도 계산 가능한 형태로 변환할 수 있다는 것을 보인 것입니다. Fisher Divergence를 전개하면:
$$ J(\theta) = \frac{1}{2} \mathbb{E}_{p_{\text{data}}} \left[ \|s_\theta(x)\|^2 \right] - \mathbb{E}_{p_{\text{data}}} \left[ s_\theta(x)^\top \nabla_x \log p_{\text{data}}(x) \right] + \text{const} $$
핵심은 두 번째 항입니다. 부분 적분(integration by parts)을 적용하면, 적절한 경계 조건 하에서:
$$ \mathbb{E}_{p_{\text{data}}} \left[ s_\theta(x)^\top \nabla_x \log p_{\text{data}}(x) \right] = -\mathbb{E}_{p_{\text{data}}} \left[ \nabla_x \cdot s_\theta(x) \right] $$
여기서 $\nabla_x \cdot s_\theta(x) = \sum_{i=1}^{d} \frac{\partial s_{\theta,i}(x)}{\partial x_i}$는 Score의 발산(divergence)입니다. 따라서 Fisher Divergence는 다음과 동치입니다:
$$ J_{\text{ESM}}(\theta) = \mathbb{E}_{p_{\text{data}}} \left[ \frac{1}{2} \|s_\theta(x)\|^2 + \nabla_x \cdot s_\theta(x) \right] $$
이것이 Explicit Score Matching(ESM) 목적함수입니다. 놀랍게도 이 식에는 $\nabla_x \log p_{\text{data}}(x)$가 나타나지 않습니다. 오직 모델의 Score $s_\theta(x)$와 그 발산만 필요합니다.
6.2.3 Explicit Score Matching의 한계
ESM은 이론적으로 우아하지만 실용적인 한계가 있습니다. 발산 항 $\nabla_x \cdot s_\theta(x)$를 계산하려면 Score의 각 성분에 대해 편미분을 계산해야 합니다. 신경망이 $d$차원 입력을 받는다면, 이는 $d$번의 역전파를 필요로 합니다. 고차원 데이터(예: 이미지)에서는 이 계산 비용이 prohibitive합니다.
이 문제를 해결하기 위한 두 가지 주요 접근법이 있습니다. Sliced Score Matching은 무작위 방향으로 투영하여 발산 계산을 단순화합니다. Denoising Score Matching은 완전히 다른 관점에서 접근하여 발산 계산 자체를 회피합니다. 다음 절에서 Denoising Score Matching을 자세히 살펴봅니다.
6.3 Denoising Score Matching
Vincent (2011)는 Score Matching과 Denoising Autoencoder 사이의 깊은 연결을 발견했습니다. 이 연결은 고차원 데이터에서도 효율적으로 Score를 학습할 수 있는 길을 열었으며, 현대 Score-based 생성 모델의 기초가 되었습니다.
6.3.1 핵심 아이디어
Denoising Score Matching(DSM)의 핵심 아이디어는 다음과 같습니다. 원본 데이터 $x$에 노이즈를 추가하여 $\tilde{x}$를 만들고, 노이즈가 섞인 분포 $q_\sigma(\tilde{x})$의 Score를 학습합니다. 놀랍게도 이 노이즈 섞인 분포의 Score는 명시적으로 계산할 수 있습니다.
가우시안 노이즈를 사용한다고 합시다:
$$ q_\sigma(\tilde{x}|x) = \mathcal{N}(\tilde{x}; x, \sigma^2 \mathbf{I}) $$
즉, $\tilde{x} = x + \sigma \epsilon$ (여기서 $\epsilon \sim \mathcal{N}(0, \mathbf{I})$). 이때 조건부 분포의 Score는:
$$ \nabla_{\tilde{x}} \log q_\sigma(\tilde{x}|x) = -\frac{\tilde{x} - x}{\sigma^2} = -\frac{\epsilon}{\sigma} $$
이 식은 놀라울 정도로 단순합니다. 노이즈가 섞인 분포의 Score(원본 데이터가 주어졌을 때)는 단순히 추가된 노이즈를 $-\sigma$로 스케일링한 것입니다.
6.3.2 DSM 목적함수
Vincent (2011)는 다음을 증명했습니다. 노이즈가 섞인 주변 분포 $q_\sigma(\tilde{x}) = \int q_\sigma(\tilde{x}|x) p_{\text{data}}(x) dx$에 대해, 다음 두 목적함수가 동치입니다:
$$ J_{\text{ESM}_\sigma}(\theta) = \frac{1}{2} \mathbb{E}_{q_\sigma(\tilde{x})} \left[ \| s_\theta(\tilde{x}) - \nabla_{\tilde{x}} \log q_\sigma(\tilde{x}) \|^2 \right] $$ $$ J_{\text{DSM}}(\theta) = \frac{1}{2} \mathbb{E}_{p_{\text{data}}(x)} \mathbb{E}_{q_\sigma(\tilde{x}|x)} \left[ \| s_\theta(\tilde{x}) - \nabla_{\tilde{x}} \log q_\sigma(\tilde{x}|x) \|^2 \right] $$
핵심은 $J_{\text{DSM}}$이 $\nabla_{\tilde{x}} \log q_\sigma(\tilde{x})$를 필요로 하지 않는다는 것입니다. 대신 $\nabla_{\tilde{x}} \log q_\sigma(\tilde{x}|x)$만 있으면 되며, 이는 위에서 보았듯이 $-(\tilde{x} - x)/\sigma^2$로 명시적으로 알려져 있습니다.
가우시안 노이즈의 경우, DSM 목적함수는 다음과 같이 단순화됩니다:
$$ J_{\text{DSM}}(\theta) = \frac{1}{2\sigma^2} \mathbb{E}_{x \sim p_{\text{data}}} \mathbb{E}_{\epsilon \sim \mathcal{N}(0, \mathbf{I})} \left[ \| \sigma \cdot s_\theta(x + \sigma\epsilon) + \epsilon \|^2 \right] $$
이를 재정리하면:
$$ J_{\text{DSM}}(\theta) = \frac{1}{2} \mathbb{E}_{x, \epsilon} \left[ \| s_\theta(x + \sigma\epsilon) + \frac{\epsilon}{\sigma} \|^2 \right] $$
6.3.3 DSM과 Denoising의 연결
DSM 목적함수를 다시 살펴봅시다:
$$ J_{\text{DSM}}(\theta) \propto \mathbb{E}_{x, \epsilon} \left[ \| s_\theta(x + \sigma\epsilon) + \frac{\epsilon}{\sigma} \|^2 \right] $$
만약 우리가 노이즈 $\epsilon$을 예측하는 신경망 $\epsilon_\theta(\tilde{x})$를 학습한다면, 최적의 예측기는:
$$ \epsilon_\theta^*(\tilde{x}) = -\sigma \cdot s_\theta^*(\tilde{x}) = -\sigma \cdot \nabla_{\tilde{x}} \log q_\sigma(\tilde{x}) $$
즉, 노이즈 예측과 Score 예측은 스케일링 인자를 제외하고 동일합니다. 이것이 바로 DDPM에서 노이즈 예측이 Score 학습과 연결되는 이유입니다.
6.4 다중 스케일 노이즈의 필요성
DSM은 효율적인 Score 학습을 가능케 하지만, 단일 노이즈 스케일 $\sigma$만 사용하면 문제가 있습니다. Song과 Ermon (2019)은 이 문제를 명확히 밝히고 해결책을 제시했습니다.
6.4.1 매니폴드 가설과 Score 추정의 어려움
매니폴드 가설(manifold hypothesis)에 따르면, 고차원 데이터(예: 자연 이미지)는 실제로 저차원 매니폴드 위에 놓여 있습니다. 예를 들어, $256 \times 256$ 이미지는 $256^2 \cdot 3 \approx 200,000$ 차원 공간에 있지만, 실제 자연 이미지가 차지하는 영역은 훨씬 작은 차원의 부분공간입니다.
이 매니폴드 가설은 Score 추정에 심각한 문제를 야기합니다.
문제 1: 정의되지 않는 Score. 데이터가 저차원 매니폴드 위에 있다면, 매니폴드 바깥에서는 $p_{\text{data}}(x) = 0$이므로 $\log p_{\text{data}}(x) = -\infty$이고, Score가 정의되지 않습니다.
문제 2: 부정확한 추정. 데이터 밀도가 낮은 영역에서는 훈련 샘플이 거의 없으므로 Score 추정이 부정확해집니다. 하지만 이 영역이야말로 샘플링 초기 단계에서 중요한 영역입니다.
6.4.2 노이즈 섭동을 통한 해결
Song과 Ermon (2019)의 해결책은 데이터에 노이즈를 추가하여 매니폴드를 "부풀리는" 것입니다. 노이즈가 추가된 분포 $q_\sigma(\tilde{x})$는 전체 공간에 대해 양의 밀도를 가지므로, Score가 어디서나 잘 정의됩니다.
그러나 노이즈 스케일 선택에는 트레이드오프가 있습니다. 큰 $\sigma$를 사용하면 Score가 공간 전체에서 잘 정의되고 추정이 안정적이지만, 원본 데이터 분포에서 많이 벗어납니다. 작은 $\sigma$를 사용하면 원본 분포에 가깝지만, 저밀도 영역에서의 추정이 부정확합니다.
6.4.3 Noise Conditional Score Networks (NCSN)
Song과 Ermon (2019)은 이 딜레마를 해결하기 위해 다중 스케일 노이즈를 사용할 것을 제안했습니다. 여러 노이즈 레벨 $\{\sigma_i\}_{i=1}^{L}$을 기하 수열로 설정합니다:
$$ \sigma_1 > \sigma_2 > \cdots > \sigma_L $$
여기서 $\sigma_1$은 충분히 커서 노이즈가 섞인 데이터가 전체 공간을 커버하고, $\sigma_L$은 충분히 작아서 원본 데이터와 거의 구분이 안 됩니다.
Noise Conditional Score Network(NCSN) $s_\theta(x, \sigma)$는 데이터 $x$와 노이즈 레벨 $\sigma$를 입력으로 받아, 해당 노이즈 레벨에서의 Score를 출력합니다. 학습 목표는:
$$ \mathcal{L}(\theta) = \sum_{i=1}^{L} \lambda(\sigma_i) \mathbb{E}_{x \sim p_{\text{data}}} \mathbb{E}_{\tilde{x} \sim q_{\sigma_i}(\tilde{x}|x)} \left[ \| s_\theta(\tilde{x}, \sigma_i) + \frac{\tilde{x} - x}{\sigma_i^2} \|^2 \right] $$
여기서 $\lambda(\sigma_i)$는 각 노이즈 레벨에 대한 가중치입니다. Song과 Ermon (2019)은 $\lambda(\sigma) = \sigma^2$를 선택하면 모든 노이즈 레벨에서 손실의 크기가 비슷해진다는 것을 보였습니다.
6.5 Langevin Dynamics를 통한 샘플링
Score Function을 학습했다면, 이제 이를 사용하여 데이터 분포에서 샘플을 생성해야 합니다. Langevin Dynamics는 Score를 활용한 샘플링의 핵심 도구입니다.
6.5.1 Langevin Dynamics의 정의
Langevin Dynamics는 다음의 확률 미분 방정식(SDE)으로 정의됩니다:
$$ dx = \frac{1}{2} \nabla_x \log p(x) \, dt + dw $$
여기서 $w$는 표준 브라운 운동(Brownian motion)입니다. 이 SDE의 핵심 특성은 시간이 무한대로 갈 때 분포가 $p(x)$로 수렴한다는 것입니다 (Roberts & Tweedie, 1996).
이산화된 버전인 Langevin Monte Carlo(LMC)는 다음과 같습니다:
$$ x_{k+1} = x_k + \frac{\eta}{2} \nabla_x \log p(x_k) + \sqrt{\eta} \, z_k, \quad z_k \sim \mathcal{N}(0, \mathbf{I}) $$
여기서 $\eta$는 스텝 사이즈입니다. 스텝 사이즈가 충분히 작고 스텝 수가 충분히 많으면, $x_k$의 분포는 $p(x)$에 수렴합니다.
6.5.2 직관적 이해
Langevin Dynamics는 두 가지 힘의 균형으로 이해할 수 있습니다.
그래디언트 항 $\frac{\eta}{2} \nabla_x \log p(x_k)$는 확률 밀도가 높은 방향으로 입자를 끌어당깁니다. 이것만 있다면 입자는 결국 분포의 모드(최빈값)에 수렴할 것입니다.
노이즈 항 $\sqrt{\eta} \, z_k$는 무작위 섭동을 추가하여 입자가 공간을 탐색하도록 합니다. 이 노이즈 덕분에 입자는 여러 모드를 탐색할 수 있습니다.
이 두 힘이 균형을 이루면, 입자의 정상 분포(stationary distribution)가 정확히 $p(x)$가 됩니다.
6.5.3 Annealed Langevin Dynamics
다중 스케일 Score(NCSN)를 사용한 샘플링을 위해 Song과 Ermon (2019)은 Annealed Langevin Dynamics를 제안했습니다. 아이디어는 큰 노이즈 레벨에서 시작하여 점차 작은 노이즈 레벨로 진행하는 것입니다.
알고리즘은 다음과 같습니다:
1. $x_0 \sim \mathcal{N}(0, \sigma_1^2 \mathbf{I})$로 초기화합니다.
2. 각 노이즈 레벨 $i = 1, 2, \ldots, L$에 대해:
a. $T$번의 Langevin 스텝을 수행합니다:
$x \leftarrow x + \frac{\eta_i}{2} s_\theta(x, \sigma_i) + \sqrt{\eta_i} \, z$
3. 최종 $x$를 샘플로 반환합니다.
이 절차의 직관은 다음과 같습니다. 높은 노이즈 레벨($\sigma_1$)에서는 분포의 모드들이 뭉개져 있어서 전역적 탐색이 용이합니다. 노이즈 레벨을 줄여가면서 점차 세부 구조를 복원합니다. 최종적으로 낮은 노이즈 레벨($\sigma_L$)에서는 거의 원본 데이터 분포에서 샘플링합니다.
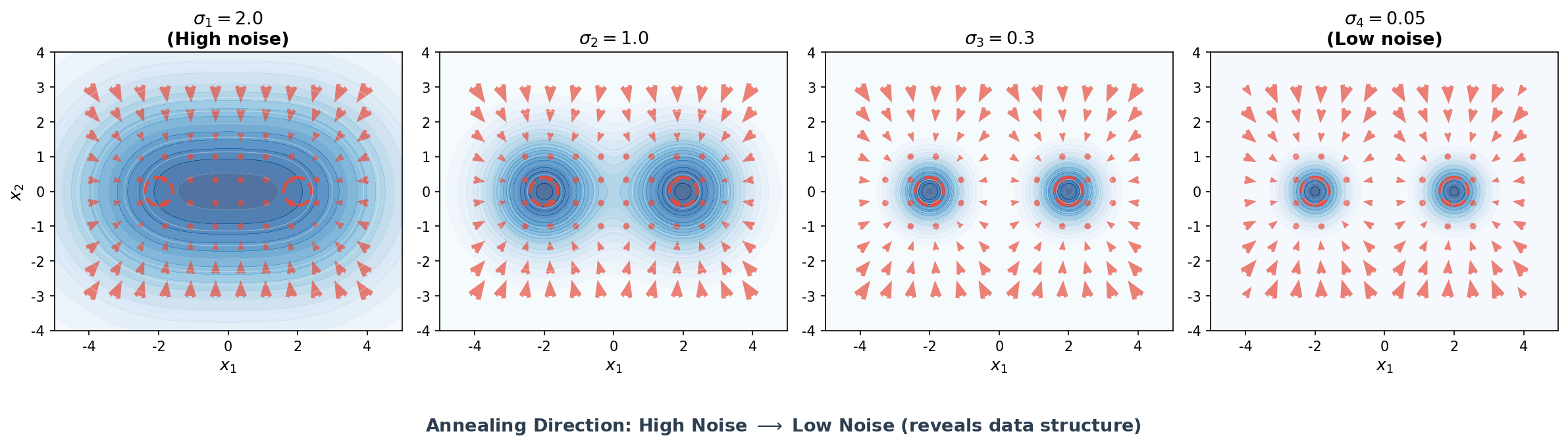
6.6 DDPM과 Score-based Models의 통합
이제 DDPM과 Score-based Generative Models 사이의 깊은 연결을 명확히 할 수 있습니다. 5장에서 유도한 결과들을 Score의 관점에서 재해석해 봅시다.
6.6.1 노이즈 예측과 Score 예측의 등가성
DDPM에서 학습하는 신경망 $\epsilon_\theta(x_t, t)$는 시간 $t$에서 추가된 노이즈를 예측합니다. 한편 Score-based 모델에서 학습하는 신경망 $s_\theta(x, \sigma)$는 노이즈가 섞인 분포의 Score를 예측합니다.
4장에서 유도한 Forward Process의 closed-form을 상기합시다:
$$ x_t = \sqrt{\bar{\alpha}_t} \, x_0 + \sqrt{1-\bar{\alpha}_t} \, \epsilon, \quad \epsilon \sim \mathcal{N}(0, \mathbf{I}) $$
이는 $x_0$에 분산 $1-\bar{\alpha}_t$의 가우시안 노이즈를 추가한 것과 같습니다. 따라서 노이즈가 섞인 분포의 Score는:
$$ \nabla_{x_t} \log q(x_t | x_0) = -\frac{x_t - \sqrt{\bar{\alpha}_t} x_0}{1-\bar{\alpha}_t} = -\frac{\epsilon}{\sqrt{1-\bar{\alpha}_t}} $$
이로부터 노이즈 예측기 $\epsilon_\theta$와 Score $s_\theta$ 사이의 관계를 얻습니다:
$$ s_\theta(x_t, t) = -\frac{\epsilon_\theta(x_t, t)}{\sqrt{1-\bar{\alpha}_t}} $$
혹은 동치적으로:
$$ \epsilon_\theta(x_t, t) = -\sqrt{1-\bar{\alpha}_t} \cdot s_\theta(x_t, t) $$

6.6.2 세 가지 동등한 파라미터화
5장에서 언급한 세 가지 파라미터화인 노이즈 예측, $x_0$ 예측, Score 예측이 수학적으로 등가임을 이제 명확히 할 수 있습니다.
노이즈 예측 $\epsilon_\theta(x_t, t)$:
$$ \hat{x}_0 = \frac{x_t - \sqrt{1-\bar{\alpha}_t} \, \epsilon_\theta(x_t, t)}{\sqrt{\bar{\alpha}_t}} $$
$x_0$ 예측 $\hat{x}_\theta(x_t, t)$:
$$ \epsilon = \frac{x_t - \sqrt{\bar{\alpha}_t} \, \hat{x}_\theta(x_t, t)}{\sqrt{1-\bar{\alpha}_t}} $$
Score 예측 $s_\theta(x_t, t)$:
$$ \hat{x}_0 = \frac{x_t + (1-\bar{\alpha}_t) s_\theta(x_t, t)}{\sqrt{\bar{\alpha}_t}} $$
세 번째 식은 5장에서 소개한 Tweedie's Formula의 직접적인 결과입니다. Tweedie's Formula는 노이즈가 섞인 관측치로부터 원본의 최적 추정치(posterior mean)를 Score로 표현합니다:
$$ \mathbb{E}[x_0 | x_t] = x_t + (1-\bar{\alpha}_t) \nabla_{x_t} \log q(x_t) $$
6.6.3 DDPM Sampling의 Score 관점 해석
DDPM의 샘플링 과정을 Score의 관점에서 재해석할 수 있습니다. 5장에서 유도한 DDPM 샘플링 공식:
$$ x_{t-1} = \frac{1}{\sqrt{\alpha_t}} \left( x_t - \frac{\beta_t}{\sqrt{1-\bar{\alpha}_t}} \epsilon_\theta(x_t, t) \right) + \sigma_t z $$
Score 관계 $\epsilon_\theta = -\sqrt{1-\bar{\alpha}_t} \cdot s_\theta$를 대입하면:
$$ x_{t-1} = \frac{1}{\sqrt{\alpha_t}} \left( x_t + \beta_t \cdot s_\theta(x_t, t) \right) + \sigma_t z $$
이는 Langevin Dynamics의 이산화와 매우 유사한 형태입니다. DDPM의 Reverse Process는 본질적으로 시간에 따라 변하는 Score를 사용한 Langevin-like 샘플링으로 볼 수 있습니다.
6.7 Score-based 접근의 장점과 한계
Score-based 관점은 생성 모델링에 여러 장점을 제공합니다. 동시에 알아야 할 한계도 있습니다.
6.7.1 장점
정규화 상수 회피: Score는 분배 함수(partition function)와 무관하므로, 정규화가 어려운 모델도 쉽게 학습할 수 있습니다.
유연한 아키텍처: GAN처럼 특별한 아키텍처 제약(예: generator-discriminator 구조)이 필요 없습니다. 어떤 신경망이든 Score 추정기로 사용할 수 있습니다.
안정적인 학습: GAN과 달리 적대적 학습이 필요 없어서 mode collapse 등의 문제가 없습니다.
이론적 보장: Langevin Dynamics의 수렴 이론 덕분에, 충분한 스텝과 적절한 학습 하에서 정확한 샘플링이 보장됩니다.
역문제 해결: Score를 알면 베이즈 역문제(image inpainting, super-resolution 등)를 별도 학습 없이 해결할 수 있습니다.
6.7.2 한계
느린 샘플링: Langevin Dynamics는 수렴을 위해 많은 스텝이 필요합니다. 이는 샘플링 속도를 제한합니다.
노이즈 레벨 설계: 적절한 노이즈 스케줄 설계가 중요하며, 이는 여전히 휴리스틱에 의존합니다.
고차원에서의 스케일링: 매우 고차원(예: 고해상도 이미지)에서는 여전히 계산 비용이 높습니다.
6.8 요약
이번 장에서 우리는 Score Function의 개념과 Score Matching의 다양한 형태를 깊이 탐구했습니다.
Score Function $s(x) = \nabla_x \log p(x)$는 로그 밀도의 그래디언트로, 정규화 상수에 독립적이라는 핵심 특성을 가집니다. Explicit Score Matching(Hyvärinen, 2005)은 부분 적분을 통해 Fisher Divergence를 계산 가능한 형태로 변환하지만, 발산 계산의 비용이 높습니다. Denoising Score Matching(Vincent, 2011)은 노이즈를 추가한 분포의 Score를 학습함으로써 발산 계산을 회피합니다. 다중 스케일 노이즈와 NCSN(Song & Ermon, 2019)은 매니폴드 가설로 인한 문제를 해결합니다. Langevin Dynamics는 Score를 사용하여 분포에서 샘플링하는 원리적인 방법을 제공합니다. DDPM의 노이즈 예측과 Score 예측은 $\epsilon_\theta = -\sqrt{1-\bar{\alpha}_t} \cdot s_\theta$의 관계로 수학적으로 등가입니다.
참고문헌
- Hyvärinen, A. (2005). Estimation of Non-Normalized Statistical Models by Score Matching. Journal of Machine Learning Research, 6, 695-709.
- Vincent, P. (2011). A Connection Between Score Matching and Denoising Autoencoders. Neural Computation, 23(7), 1661-1674.
- Song, Y., & Ermon, S. (2019). Generative Modeling by Estimating Gradients of the Data Distribution. Advances in Neural Information Processing Systems, 32, 11895-11907. arXiv:1907.05600
- Ho, J., Jain, A., & Abbeel, P. (2020). Denoising Diffusion Probabilistic Models. Advances in Neural Information Processing Systems, 33, 6840-6851. arXiv:2006.11239
- Song, Y., Sohl-Dickstein, J., Kingma, D. P., Kumar, A., Ermon, S., & Poole, B. (2021). Score-Based Generative Modeling through Stochastic Differential Equations. International Conference on Learning Representations. arXiv:2011.13456
- Roberts, G. O., & Tweedie, R. L. (1996). Exponential Convergence of Langevin Distributions and Their Discrete Approximations. Bernoulli, 2(4), 341-363.
- Efron, B. (2011). Tweedie's Formula and Selection Bias. Journal of the American Statistical Association, 106(496), 1602-1614.
'인공지능 논문 정리 > Diffusiion' 카테고리의 다른 글
| [Diffusion 5] DDPM 논문 완전 정복 (하): Reverse Process와 학습 (0) | 2026.01.19 |
|---|---|
| [Diffusion 4] DDPM 논문 완전 정복 (상): Forward Process (0) | 2026.01.18 |
| [Diffusion 3] Diffusion을 위한 확률론: 가우시안, 마르코프 체인, 그리고 베이즈 (0) | 2026.01.18 |
| [Diffusion 2] Forward와 Reverse: Diffusion의 두 가지 여정 (1) | 2026.01.18 |
| [Diffusion 1] 노이즈에서 이미지로: Diffusion Model의 기본 원리 (0) | 2026.01.18 |


